No, tranquilli. Non stiamo insinuando nessuna correlazione tra il 5G e i terremoti. Che poi, parlandoci chiaro, non sarebbe meno sensata di quelle con i vaccini, con il coronavirus o con più o meno imprecisate “morie di volatili”.
Stiamo parlando invece di un progetto di Google. Ma andiamo con ordine. Partiamo da ShakeAlert… cosa è?
ShakeAlert
ShakeAlert® é un sistema di allerta precoce per i terremoti gestito dal U.S. Geological Survey (l’USGS è un po’ l’equivalente statunitense del nostro Istituto Nazionale di Geofisica e Vulcanologia).
ShakeAlert opera una rete di sismometri (sensori in grado di rilevare la presenza di attività sismica) lungo tutta la costa occidentale degli Stati Uniti. Ricordiamo che quella zona, ed in particolar modo la California, è una zona densamente popolata e molto sismica, in quanto si trova sulla cosiddetta faglia di Sant’Andrea, un “punto” di frizione tra la placca nordamericana e quella pacifica.
Tutti i ricercatori sono purtroppo concordi nell’affermare che, in quella zona, la probabilità che ci sia un terremoto catastrofico nei prossimi anni è elevatissima. Gli hanno già dato un soprannome, “The Big One” (“Quello Grosso”).
Google, che ha il suo quartier generale proprio nella California del Sud, a Mountain View, non poteva restare indifferente a questo problema.
Il sistema ShakeAlert, con la sua rete di sismometri, tutti collegati ad un centro di elaborazione, riesce a rilevare in maniera molto efficiente i terremoti, a elaborarne epicentro e intensità e a mettere a disposizione degli avvisi in tempo reale.
Come è possibile?
Per capirlo dobbiamo fare una piccola digressione e capire come si propaga la forza distruttrice del terremoto. Chiedo venia in anticipo ai geologi e sismologi che dovessero trovarsi a leggere questo articolo 🙂 ma ho ovviamente dovuto fare delle (necessarie) semplificazioni.
Un terremoto si propaga principalmente con due tipologie di onde, le onde P e le onde S.
Propagazione delle onde P
Propagazione delle onde S
La velocità con cui si propagano dipende dal tipo di terreno in cui ci troviamo, ma possiamo considerare dei valori medi.
Le onde P, quelle più veloci, viaggiano a oltre 7 km al secondo;
Le onde S, più lente ma decisamente più distruttive, viaggiano a oltre 4 km al secondo.
Sembrano velocità molto alte, in effetti.
Ma dobbiamo paragonarle con una rete di telecomunicazioni attuale, ovvero dobbiamo capire quanto ci vuole a trasmettere un’informazione tra due sistemi attraverso la rete Internet. Prendiamo ad esempio il cosiddetto Ping Time (ovvero il tempo di viaggio di un “pacchetto” internet) tra Los Angeles e San Diego. Stiamo parlando di circa 200 km che vengono coperti, in media, in meno di 3.8 millisecondi, ovvero 0.0038 secondi. Cioè, reggetevi, quel pacchetto viaggia ad una velocità di oltre cinquantaduemila km al secondo!
La cosa non dovrebbe stupire, in quanto, giusto per paragone, a “bordo” di Internet riusciamo a fare mezzo giro intorno al mondo (ad esempio da Roma ad Auckland, in Nuova Zelanda) in meno di un terzo di secondo (circa 0.324 secondi in media).
Quindi la velocità dei sistemi di telecomunicazione e, analogamente, di quelli informatici (per la parte di elaborazione) riesce fortunatamente a “battere”, e di gran lunga, la velocità di propagazione dei terremoti.
Quindi un sismometro che si trova vicino all’epicentro di un ipotetico terremoto è in grado di inviare in “tempo reale”, ovvero in un tempo molto inferiore a quello di propagazione del terremoto stesso, un segnale al centro di elaborazione.
Ed è qui che entra in gioco Google.
Il messaggio di allerta risultante infatti, viene propagato agli smartphone Android che si trovano nella zona d’interesse che mostreranno quindi un messaggio di questo tipo:
Il messaggio invita appunto ad abbassarsi, trovare riparo e afferrare la struttura sotto cui ci si ripara, secondo le direttive del California Office of Emergency Services.
Il sistema ShakeAlert funziona in configurazione “ufficiale” (ovvero dopo diversi anni di funzionamento in modalità di test) dal 17 ottobre 2019 e Google ha iniziato a “rilanciare” i messaggi di allerta su tutti i telefoni Android a partire dall’11 agosto 2020. Dopo la California si sono recentemente aggiunti Oregon e Washington, completando tutta la costa occidentale. Purtroppo sembra che Apple non sia molto interessata alla cosa, almeno secondo una recente intervista a Doug Given, coordinatore del progetto ShakeAlert per USGS.
Prestazioni
Ma quali sono le prestazioni del sistema? In pratica, quanti secondi di preavviso riusciamo a spuntare prima che le pareti inizino a tremare?
Il sistema ha una soglia di attivazione, fissata al 5 grado della scala Richter. Questo per evitare che messaggi di allarme vengano mandati anche per piccole scosse non pericolose ed anche perché, paradossalmente, il tempo di preavviso più grande si ottiene per i terremoti più potenti: quest’ultimi si propagano più lontano e il messaggio “informativo” guadagna molto più “terreno” rispetto alla forza distruttiva dell’onda sismica.
Questa premessa è necessaria perché, dopo l’entrata in funzione definitiva del sistema, gli allarmi si sono attivati solo il 5 luglio del 2019 (quindi prima del collegamento con Google), in occasione delle scosse più intense nella cosiddetta sequenza Ridgecrest. Fortunatamente direi.
I due terremoti più forti di quella sequenza, rispettivamente di 6.4 e 7.1 gradi della scala Richter, hanno generato degli allarmi che sono arrivati con ben 45 secondi di anticipo sulle onde S delle scosse. I nostri calcoli sono esatti: Ridgecrest è una località che si trova più o meno a 200 chilometri dall’oceano e quindi le onde S (che, ricordiamolo, viaggiano a circa 4 km/s) hanno impegnato una cinquantina di secondi (forse anche meno) per raggiungere le zone costiere, quelle più densamente popolate. Le informazioni e il messaggio di allerta, è semplice calcolarlo per differenza, ci hanno messo meno di 5 secondi.
Purtroppo però, proprio perché la collaborazione con Google ancora non era attiva, gli allarmi sono arrivati solo ai pochi utenti di un’applicazione specifica.
Google vuole e può far da sé
Tutto questo è eccezionalmente bello e funzionale. E soprattutto, come si può ben capire, dannatamente utile.
Ma presuppone l’esistenza di una rete di sismometri, tutti collegati in tempo reale ad un centro di elaborazione.
Ovvio che quindi questo sistema non può essere replicato in tutto il mondo. Questo è veramente un problema, perché esistono altre zone altamente sismiche, densamente popolate ma prive un sistema di allerta precoce così raffinato come quello degli Stati Uniti.
Al solito la soluzione è davanti ai nostri occhi o, più probabilmente, nelle nostre tasche.
Ogni smartphone moderno è dotato infatti di un accelerometro che, fatte le dovute proporzioni per quanto riguarda accuratezza ed efficienza, è essenzialmente analogo ad un sismometro.
Ma a cosa serve un accelerometro in uno smartphone? A misurare gli spostamenti a cui il telefonino è sottoposto, ad esempio. Insieme al suo compagno inseparabile, il giroscopio, è in grado di fornire sempre una posizione del dispositivo rispetto all’ambiente che lo circonda. Può aiutarci a contare i nostri passi o a capire l’orientamento dello schermo del telefonino stesso, in modo che il nostro video su YouTube assuma la forma più adatta.
Come abbiamo detto, però, gli accelerometri degli smartphone sono molto meno precisi e soprattutto sono sottoposti a vibrazioni (un sismometro é fissato in modo solidale al terreno, mentre i telefonini, per definizione, stanno in tasca, su un tavolo, su un’auto…).
Ma hanno un indubbio vantaggio. Ce ne sono moltissimi! E sono, per definizione, tutti connessi in rete (che sia 5G o meno).
Google è sicuramente uno dei leader in quello che si chiama il settore dei Big Data, cioè l’analisi (in questo caso in tempo reale) di un numero impressionante di dati, sia per frequenza temporale che per numero di sorgenti.
Non solo, Google ha anche molte competenze, per usare un eufemismo, nel Machine Learning: in pratica, non deve “insegnare” ai suoi sistemi come riconoscere un terremoto, ma può far sì che gli stessi sistemi, analizzando i dati a posteriori, siano in grado, in modo autonomo, di apprendere la correlazione tra i dati forniti dagli accelerometri dei telefonini e la presenza (o meno) di un’onda sismica. Imparare dalla storia passata per riconoscere gli eventi del presente.
E’ proprio per questo che, ad esempio, in occasione della scossa di terremoto avvenuta a Milano il 17 dicembre 2020, a chiunque cercasse notizie relative al sisma su un dispositivo mobile nell’area milanese è apparsa una richiesta del genere:
In pratica Google chiedeva un riscontro “umano” per poi affinare i propri algoritmi.
Il progetto è ormai oltre la fase di debutto. Google ha infatti annunciato ad aprile scorso l’attivazione di Android Earthquake Alerts System in tutto il mondo, a partire dalla Grecia e dalla Nuova Zelanda. I prossimi paesi ad essere attivati, e che sono attualmente in fase di test, saranno Kazakistan, Repubblica del Kirghizistan, Filippine, Tagikistan, Turchia, Turkmenistan e Uzbekistan. Nel corso del 2022 ne è prevista l’attivazione a livello globale.
Le notizie appena arrivate dal lato turco del Mar Egeo fanno ben capire come questa tecnologia può seriamente salvare molte vite umane anche se, al momento, in Turchia, fortunatamente, non si segnalano vittime.
No, non sto parlando di una tastiera in particolare. C’è anche sulla vostra, come su tutte le tastiere italiane (lo sapete vero che la disposizione dei tasti varia leggermente nazione per nazione?); su quelle inglesi è ancora più in vista, ma è possibile trovarlo su tutte, davvero su tutte le tastiere “fisiche”, quelle in plastica per intenderci… su quelle degli smartphone spesso è un po’ nascosto, si trova tra i simboli.
Certo, non ha diritto a un tasto tutto suo… da noi, in Italia, divide lo spazio con la o accentata (ò) e la c con la cediglia (ç). All’inizio era considerato addirittura meno importante di quest’ultima: la c con la cediglia infatti appare con la contemporanea pressione del tasto delle maiuscole, mentre per far apparire il papero bisogna premere il tasto Alt Gr (e, datemi retta, Alt Gr non è un tasto molto conosciuto). Oppure, e questo magari per alcuni sarà una novità, se avete una tastiera con il tastierino numerico nella parte destra, potete provare a digitare 6 4 sul tastierino mentre tenete premuto il tasto Alt.
Insomma, avete capito di che cosa sto parlando?
Eccolo qui. “At” per i più professionali. La “chiocciola” per i più informali.
Ma in ogni paese del mondo è chiamato in un modo diverso.
Il termine “chiocciola”, infatti, è conosciuto solo in Italia. I greci, per svelare il gioco di parole alla base del titolo del post, lo chiamano amichevolmente Παπάκι (Papáki, letteralmente piccolo papero, anatroccolo). In alcuni paesi scandinavi è invece una “coda di gatto”, ma il nomignolo che va per la maggiore nel mondo è “coda di scimmia”.
La cosa più stupefacente di questo segno tipografico che per molti, quasi tutti, rappresenta un po’ il simbolo di questa “era digitale” (dalle email per arrivare fino a molti social network) è che ha invece origini molto antiche.
Gli albori
La prima apparizione della @ risale infatti al 1345.
Ma dobbiamo fare un ulteriore passo indietro, intorno al 1150. Costantino Manasse, uno storico bizantino, scrive “Cronaca universale” (Χρονική σύνοψις), un componimento in versi in lingua greca. Si tratta di un manuale di storia, che tratta dalla creazione del mondo fino al 1081, anno in cui Alessio I Comneno, imperatore bizantino, sale al trono.
Si trattava infatti di un’opera puramente celebrativa, dedicata alla sposa dell’imperatore, Irene. Ma, come si direbbe con un linguaggio attuale, scoppia il “caso editoriale”!
L’opera ha un grande successo. Viene trasformata in prosa e tradotta quindi in bulgaro. Tornando nel 1345, l’edizione in prosa bulgara viene finemente illustrata con 69 miniature che rappresentano un centinaio di scene storiche. L’opera, peraltro, é attualmente conservata alla Biblioteca Apostolica Vaticana.
Miniatura 19 dalla Cronaca Universale di Costantino Manasse, 14mo secolo: Fuga di Paride ed Elena e l’inizio della guerra di Troia. Wikipedia, PD-Art
Nella miniatura numero 19, poco sopra ad una nave che riporta gli innamorati Paride ed Elena verso Troia, ecco apparire come prima lettera della parola “Amin” (Amen) la nostra chiocciola!
In questo caso non è associato alla chiocciola alcun significato particolare: potrebbe semplicemente essere il parto della fantasia di un amanuense particolarmente ispirato. Insomma si tratta di quello che potremmo chiamare una “meteora”, un’apparizione singola e slegata da qualsiasi tipo di significato o contesto.
Le origini
Facciamo un passo indietro, anzi in avanti, come in un film di Nolan. Ai giorni nostri la chiocciola viene utilizzata solo per le email? No, assolutamente no.
Innanzitutto può essere usata anche nella posta cartacea, proprio ad indicare la presenza del destinatario presso un’azienda o un’altra famiglia; sostituisce la dicitura “presso” oppure la più anglosassone “c/o” (care of).
In ingegneria meccanica ed elettronica viene utilizzata per indicare il “contesto” in cui si ottengono certe prestazioni: un apparato elettronico eroga 100 Volt @ T=25°C (alla temperatura di 25 gradi) oppure un motore di un’auto eroga 100 KW @ 5000 rpm (a 5000 giri al minuto).
Analogamente indica, in economia, il cambio di una moneta in corrispondenza di un’operazione con valuta estera (ad esempio si può dire che si possono investire 1000 AUD @ € 1,57 ovvero 1000 dollari australiani quando un euro vale 1,57 dollaro australiano) oppure il valore di un titolo quando si fa un’operazione di acquisto o di vendita (es. FCA 500 @ € 12,40 ovvero 500 azioni Fiat Chrysler Automobiles al valore di 12,40 euro ciascuna).
Da questi ultimi utilizzi ne deriva il significato “commerciale” anglosassone che si può sintetizzare come “at a price/rate of” (in italiano: “al prezzo di”) … o più semplicemente “at“, il nome con cui viene identificata ancora adesso in tutti i paesi anglosassoni, appunto. Ecco anche l’origine del suo secondo nome, “A commerciale”, a fare il paio con &, l'”E commerciale”.
Ma, ecco, torniamo al primo nome, “at”: al contrario di “chiocciola”, “coda di gatto” e “coda di scimmia”, è assolutamente distinto dall’aspetto grafico del segno. E sarà proprio per questo che da “at” parte il primo studio sull’origine del carattere.
La prima teoria
Nel 1932, infatti, Berthold Louis Ullman, uno dei più importanti latinisti statunitensi della sua epoca, nonché paleografo (cioè studioso della scrittura in tutti i suoi aspetti storici), afferma[1]Ullman, B. L. (1932). Ancient Writing and its Influence. London, England: Longmans, Greens and Co. – pag. 187, archive.org che tra le legature latine “esiste anche il segno @ che sta in realtà per ad, con una d onciale esagerata“.
There is also the sign @, which is really for ad, with an exaggerated uncial d
B. L. Ullman, Ancient Writing and its Influence, Longmans, Greens and Co., 1932
Per il buon Bertoldo, insomma, la nostra chiocciola non sarebbe altro che un ad latino. Con l’utilizzo continuato, le due lettere a e d si sarebbero “fuse” assieme a formare quella che in tipografia si chiama una “legatura“. Alcuni esempi di legature latine sono costituite ad esempio dalla a e dalla e nel dittongo latino ae che diventano æ oppure la stessa “e commerciale” che abbiamo già visto in precedenza, dove la e e la t della congiunzione latina et diventano &.
Partendo da questi esempi pareva infatti abbastanza banale estendere il concetto alla nostra chiocciola, dove lo “svolazzo” intorno alla a minuscola sarebbe stato in realtà una d “arrotolata all’indietro”. Questo combaciava anche con lo stile di scrittura onciale, utilizzato dagli amanuensi latini e bizantini e più tardi, nei titoli e nelle intestazioni, fino al tredicesimo secolo.
Sarebbe stato semplice spiegare successivamente il passaggio dall’ad latino all’at anglosassone.
Ma no. Questa semplice teoria, perché più di una teoria non è, non convinceva molti studiosi.
La realtà storica infatti non è mai semplice e c’è voluto un italiano, quasi 70 anni dopo Ullman, per aggiungere un importante tassello.
La pista “toscana”
Nel 2000, infatti, Giorgio Stabile, professore di Storia della Scienza all’Università “La Sapienza” di Roma, porta a termine una ricerca in tal senso per l’Istituto Treccani.
Nessun simbolo nasce dal nulla e nessun simbolo viene scelto a caso
Giorgio Stabile, L’icon@ dei mercanti, Roma, Istituto Treccani, 2000
Nel brillante articolo intitolato “L’icon@ dei mercanti”[2]Stabile, G. (2000), L’Icon@ dei mercanti. Roma, Italia: Istituto Treccani – Internet Archive il Prof. Stabile rileva come, sebbene la denominazione “at” sia effettivamente non collegata al segno grafico, essa non sia l’unica ad avere questa caratteristica. Così come “at” è diffusa in tutto il mondo anglosassone, ne esiste un’altra, altrettanto originale e slegata dall’aspetto grafico di @, che è invece diffusa in tutta l’area di lingua spagnola, America Latina inclusa.
Si tratta della denominazione “arroba“.
Come molte parole di origine spagnola a sua volta deriva dal termine arabo rub’a, il cui significato si lega ad un’unità di misura e significa “un quarto”. Il termine, originariamente diffuso in Iraq, Egitto e Arabia, si diffonde presto in quasi tutta la penisola iberica durante la lunga occupazione saracena. Attraverso il castigliano il termine “arroba” entra a far parte del latino medievale, dove assume il significato sia di un’unità di peso (25 libbre) ma anche quello di una misura di vino.
Proprio per questo significato metrologico visibilmente collegato al commercio, il Prof. Stabile decide di addentrarsi non nella grafia onciale, roba da monasteri e amanuensi, Guglielmo di Baskerville e novizio Adso, ma di indagare invece nel campo della scrittura mercantesca, la scrittura utilizzata dai mercanti e successivamente dalla borghesia in genere tra il tredicesimo e il sedicesimo secolo.
Non posso esimermi, per mero orgoglio campanilistico, dal segnalarvi che il primo documento scritto in mercantesca è la cosiddetta Carta Pisana, un portolano (cioè una carta per la navigazione) risalente al 1275 circa.
Carta Pisana, Département des cartes et plans della Bibliothèque nationale de France, Parigi. Wikipedia, PD.
Il documento, attualmente conservato al Département des cartes et plans della Bibliothèque nationale de France, a Parigi, è sicuramente la più antica carta nautica ancora esistente e deve il suo nome al fatto di essere stata ritrovata a Pisa.
Tornando all’indagine sulla scrittura mercantesca, il nostro docente trova diversi indizi all’interno di un’opera di Federigo Melis e Elena Cecchi [3]Melis, F. & Cecchi, E. (1972). Documenti per la storia economica dei secoli XIII-XVI con una Nota di Paleografia Commerciale (per i secoli XIII-XVI). Firenze, Italia: Olschki.
La co-autrice elenca le abbreviazioni utilizzate in questo tipo di scrittura: in particolare quelle utilizzate a scopo “logistico”, diremmo oggi, ovvero per descrivere la merce e le relative unità di misura… e già all’inizio dell’elenco si nota una promettente:
“a (con svolazzo in senso antiorario) = anfora” tratto da Elena Cecchi, Nota di Paleografica Commerciale (per i secoli XIII-XVI), Firenze, Olschki, 1972. Per gentile concessione della casa editrice.
Già… ma come è questo “svolazzo in senso antiorario” attorno ad una “a”…? Non ci fidiamo, vogliamo vedere qualcosa! 🙂
Ci viene in aiuto messer Francesco Lapi da Firenze (questi toscani…), un mercante che, nei primi anni del 1500, aveva i suoi affari nella città di Siviglia. Affari e non solo, visto che si era accompagnato con una donna locale, tal Belgara, e aveva avuto anche un figlio.
Siviglia si trova vicina al porto di Cadice che, in quel periodo, è uno dei porti di interscambio con il continente americano appena scoperto. Ed è proprio a riguardo dei grandi guadagni che si possono ottenere con questi scambi che, il 4 maggio 1536, Francesco Lapi scrive una lettera a tal Filippo di Filippo Strozzi in Roma.
Trascrizione della lettera di Francesco Lapi a Filippo di Filippo Strozzi, 4 maggio 1536. Tratta da Federigo Melis, Documenti per la Storia Economica dei secoli XIII-XVI, Firenze, Olschki, 1972. Per gentile concessione della casa editrice.
Sembra che il vino fosse una materia molto ricercata e pagata bene “perché là un’anfora di vino, che è 1/30 di botte, vale 70 o 80 ducati.“
Originale della lettera di Francesco Lapi a Filippo di Filippo Strozzi, 4 maggio 1536. Tratta da Federigo Melis, Documenti per la Storia Economica dei secoli XIII-XVI, Firenze, Olschki, 1972. Per gentile concessione della casa editrice.
Immaginatevi quindi lo stupore di vedere che alla parola “anfora” corrisponde nel documento originale un segno indubitabilmente uguale alla nostra cara chiocciola.
Ecco quindi trovato il significato originale della @: l’unità di misura anfora.
Ma “arroba“? In fondo eravamo partiti da lì, ovvero da come la chiocciola viene chiamata nella maggior parte dei Paesi ispanoamericani. Bisognerebbe trovare una controprova.
Il Prof. Stabile chiude il cerchio, o meglio la chiocciola 🙂 , con una semplice ricerca su un dizionario spagnolo-latino dell’epoca. Antonio de Nebrjia lo pubblica infatti a Salamanca nel 1492, e Samuel Gili Gaya lo riporta integralmente nel Tesoro Lexicografico (1492-1726), edito a Madrid nel 1947. E proprio a pagina 226 di quest’ultima opera si trova il termine arroba, a cui viene fatta corrispondere la traduzione amphora.
Dunque, finito qui? L’ipotesi di Ullman ( ovvero @ significa ad ) è da considerare tramontata?
C’è una sola verità?
Non siamo nel campo delle scienze esatte: lo stesso Prof. Stabile ipotizza che i due significati diversi abbiano la stessa dignità e si siano fondamentalmente evoluti in due “universi” commerciali complementari e non sovrapposti, nel nord del mondo quello inglese (anglosassone), a sud quello ispano-latinoamericano.
La teoria di Ullman, comunque non suffragata al momento da prove, viene rafforzata anche dal significato che la stessa chiocciola assume in documenti leggermente più recenti, ovvero quello di “addì”, parola usata spesso, anche ai giorni nostri, nella datazione di documenti. Si noti, guarda caso, che nella stessa lettera riportata prima, la a di “addì” ha infatti la stessa grafia di una chiocciola.
Particolare della lettera di Francesco Lapi a Filippo di Filippo Strozzi, 4 maggio 1536. Tratta da Federigo Melis, Documenti per la Storia Economica dei secoli XIII-XVI, Firenze, Olschki, 1972. Per gentile concessione della casa editrice.
Questo gioca a favore di un legame tra la chiocciola e il significato “ad”, che anche oggi rimane nel utilizzo come “presso”.
Altri studiosi invece propendono per l’ipotesi che l’utilizzo come abbreviazione di anfora sia l’origine di @ che poi il simbolo si sia diffuso nel mondo anglosassone senza portarsi dietro anche il suo significato.
La revisione spagnola
Un particolare interessante in proposito si trova in alcuni documenti antecedenti alla lettera di Francesco Lapi, analizzati da Jorge Romance in un blog spagnolo [4]Romance, J. (2009, 30 giugno). La arroba no es de Sevilla (ni de Italia). Disponibile 5 febbraio, 2021, da purnas.com nel 2009.
L’autore porta infatti all’attenzione un documento che riporta la registrazione di una spedizione di grano dalla Castiglia verso il Regno di Aragona.
Taula de Ariza, 1448. Nella seconda riga, al centro, si nota un carattere simile alla @
Anche qui si nota un simbolo molto simile alla nostra chiocciola, leggermente diverso nel centro del segno, su un documento antecedente di quasi un secolo.
Ne approfitto per fare una considerazione che si applica a tutti i ragionamenti che abbiamo fatto fin qui. Stiamo parlando di scrittura “a mano”, o meglio “a penna”… quindi è ovvio aspettarsi una certa variabilità tra i caratteri, soprattutto per quello che riguarda le abbreviazioni; oltre che dalla grafia, dalla tecnica e dalla scolarizzazione dello scrittore l’aspetto dei vari segni dipende anche dal tipo di documento: un registro contabile sarà stato compilato con meno cura e più velocemente rispetto ad un contratto ufficiale, ad esempio.
Oltre a questo documento, nel blog ne appaiono altri due, a mio avviso decisamente più interessanti.
Taula de Calatayud, 1445Taula de Monzon, 1445
Questi due documenti, analoghi alla Taula de Ariza, trovati a Calatayud (che si trova vicino alla stessa Ariza, a poche decine di chilometri a sud-ovest di Saragozza) e a Monzon (sempre a poche decine chilometri da Saragozza, ma in direzione opposta) contengono quella che già ad un occhio poco esperto appare come una novità.
Il simbolo che assomiglia alla chiocciola sembra proprio nascere non da una “a” con uno “svolazzo”… bensì dalle lettere “ro“. Ciò potrebbe legare il nostro simbolo direttamente alla parola arroba e con la sua radice araba rub’a.
Fermiamoci per il momento qui. Abbiamo ancora molta strada da fare per arrivare ai nostri giorni. Ci basti sapere [5]Magno, A. M. (2016, 7 marzo). Tomlinson era un grande ma-la @ l’abbiamo inventata noi italiani non lui. Disponibile 5 febbraio, 2021, da glistatigenerali.com che da ora in poi @ inizia a diffondersi in tutto il mondo… partendo dall’Italia (Genova, Venezia, …) e non solo. Arriverà presto nel Nuovo Mondo; in una fattura [6]George Washington Papers, Series 4, General Correspondence: Horatio Gates, Stationary Invoice. 1779. Manuscript/Mixed Material, LibraryOfCongress del 20 settembre 1779 per materiale di cancelleria (destinato niente di meno che a George Washington) i prezzi unitari dei vari oggetti sono tutti preceduti da @.
Tempi “moderni”
Siamo giunti quindi nel 1800.
Il primo giugno del 1852 viene presentato, negli Stati Uniti, il brevetto numero 8980: firmato dal signor John Jones, di Clyde NY, si intitola “miglioramenti per la copiatura di manoscritti”.
Incipit del brevetto US.8980, 1 giugno 1852, Google Patents
Recita più o meno così: “Sia noto che io, John Jones, di Clyde, nella contea di Wayne e Stato di New York, ho inventato un nuovo e utile apparato o macchina con il quale una persona può copiare un manoscritto oppure scrivere i propri pensieri direttamente su carta stampata, e questo apparato o macchina io chiamo tipografo meccanico (Mechanical Typographer)…”. Apparato che ai giorni nostri è universalmente conosciuto come macchina per scrivere.
I primi prototipi assomigliavano più a macchine da cucire, la cui tecnologia avevano preso a prestito e riadattato, con risultati piuttosto approssimativi.
Anche il genio di Christopher Latham Sholes sin dal 1867 si scontrò con diversi tentativi, falliti, per lanciare la produzione in serie di un suo prototipo. Al signor Sholes dobbiamo, ad esempio, l’invenzione dello schema QWERTY, ovvero il metodo, usato tutt’oggi, per distribuire le lettere su una tastiera pensato all’epoca per minimizzare la probabilità di inceppamenti dei martelletti.
Remington No. 1, 1874. Immagine da Wikipedia, CC BY-SA 3.0.
Nel 1873 l’azienda E. Remington and Sons, con decenni di esperienza nel campo della produzione di fucili, rilevò il progetto e la macchina vide la luce e soprattutto la commercializzazione in serie a partire dal 1 luglio del 1874, ovviamente non più come Sholes&Glidden Typewriter ma con il più altisonante nome di Remington No. 1, quella che si può considerare come la prima vera macchina per scrivere.
Il primo papero su una tastiera
Ma perché tutto questo interesse per le macchine per scrivere?
Macchina per scrivere “Hammond 1”, 1889. La freccia indica il tasto che contiene X , 7/8 e il carattere @
E’ presto detto.
La nostra “A commerciale” appare [7]Houston, K. (2011, 24 luglio). The @-symbol. Disponibile 5 febbraio, 2021, da shadycharacters.co.uk per la prima volta su una “tastiera” nella macchina per scrivere compatta “Hammond 1”, in una delle sue ultime versioni (1889).
Nelle prime versioni, infatti, la chiocciola non era presente e il fatto che James Bartlet Hammond (giornalista statunitense e inventore) si sia trovato costretto ad aggiungerla implica probabilmente, e senza particolare sorpresa, che le sue macchine da scrivere abbiano avuto successo soprattutto nel campo commerciale ed economico e che la chiocciola fosse considerata indispensabile in tale settore.
L’esistenza, ma soprattutto l’importanza, del segno @ viene infatti sancita pochi anni più tardi in un manuale tecnico [8]Pasko, W. W. (1894). American Dictionary of Printing and Bookmaking. New York, USA: Howard Lockwood & Co. – Google Books edito a New York di cui, qui di seguito, potete vedere un estratto relativo:
American Dictionary of Printing and Bookmaking, New York, Howard Lockwood & Co., 1894, pagina 107.
A conferma di ciò, nel 1895, la chiocciola è invece già presente sulla prima versione della macchina per scrivere della neonata “Underwood Typewriter Company“, un’altra azienda americana con sede a New York (che, guarda i casi della vita, sarà poi acquisita nel 1963 dalla “nostra” Olivetti).
Sic transit gloria mundi, da ora in poi la nostra storia continuerà dall’altra parte dell’Oceano Atlantico.
Attacchiamo la spina!
Infatti è proprio in seguito al Censimento degli Stati Uniti del 1890, più in particolare per l’analisi della mole di dati da esso raccolto, che viene realizzato un nuovo prodigio della tecnica.
L’ingegner Herman Hollerith, un immigrato tedesco di seconda generazione, sviluppa le idee che erano state di Charles Babbage e realizza, appena in tempo, nel 1890 appunto, la “macchina tabulatrice”: una macchina in grado di elaborare in maniera veloce una grande quantità di dati, a condizione che questi dati fossero inseriti nel sistema sotto forma di schede perforate. Una matrice di aghi e dei contatti elettrici erano in grado di rilevare la presenza (o l’assenza) di un foro, incrementando opportunamente un contatore analogico.
In questo caso non ci interessa la macchina in sé, anche se essa ebbe un grandissimo successo: infatti l’azienda di Hollerith si fuse insieme ad alcune altre e la società risultante prese il nome, nel 1924, di International Business Machines Corporation. Già, l’IBM. Una multinazionale forse sconosciuta alle grandi masse, soprattutto più giovani, ma che nel 2018 aveva più di 350mila dipendenti con un fatturato di 80 miliardi di dollari.
Quello che ci interessa qui è come le informazioni venivano rappresentate sulle schede perforate.
Scheda perforata per la macchina tabulatrice di Hollerith, 1890. Wikipedia, PD.
Mentre la macchina di Hollerith utilizzava delle schede pensate apposta allo scopo (ovvero, ricordiamolo, il censimento), quando queste macchine iniziarono a diffondersi si dovette pensare ad un modo “standard” di rappresentare le informazioni: è proprio l’IBM che intorno agli anni trenta definisce il BCDIC (Binary-Coded Decimal Interchange Code), essenzialmente un codice che associa alle perforazioni su ciascuna colonna della scheda un carattere dell’alfabeto.
Scheda perforata per calcolatore, IBM 704 Fortran, anni ’50. Ogni colonna codifica un carattere. Wikipedia, CC BY 2.0
Ecco che quindi, dopo questa lunga premessa, ci poniamo la solita domanda… ma la nostra chiocciola c’era in quel codice? No, nella prima versione del BCDIC, risalente appunto agli anni trenta, la chiocciola non c’era. Immolata sull’altare della semplicità: quel codice consentiva di inserire i numeri, le lettere (maiuscole) e solo 3 altri simboli.
Ma già nella nuova versione del codice, risalente agli anni cinquanta, ecco riapparire la nostra @, insieme ad una decina di altri simboli. Ciò a ribadire l’importanza che ormai si era conquistata nel mondo degli affari e del commercio.
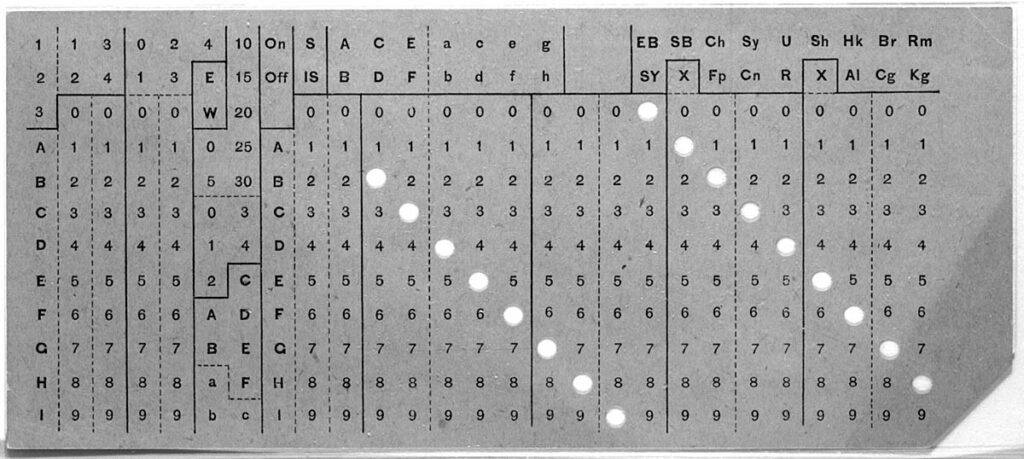
Ma dunque come si scrive chiocciola su una scheda perforata? Non so, magari per fare un biglietto da visita old-style… 😉
Scegliamo una codifica, ad esempio la IBM029, nata intorno al 1964.
Generatore di schede perforate online, codifica IBM029, TheVirtualKeypunch
In cima alla scheda vedete il testo allineato alle colonne. Il nostro simbolo @ è nella colonna 41 dove si trovano due “buchi” nelle caselle 4 e 8.
Insomma, è facile rendersi conto che con il passare degli anni le codifiche delle schede perforate evolvono e si moltiplicano. Le caratteristiche comuni a tutte sono che, per questioni di velocità e di resistenza meccanica della scheda, ogni carattere (che corrisponde ad una colonna) può essere codificato con due, al massimo tre, fori. Questo limita fortemente il numero di caratteri utilizzabili e c’è una tendenza a creare una codifica “specifica” per ogni settore di utilizzo (la programmazione, il data-entry, ecc.) allo scopo di utilizzare un insieme di caratteri piuttosto che un altro.
Presto questa proliferazione diventa non più sostenibile. Anche perché poi la tecnologia evolve e le carte perforate iniziano a non rappresentare più un limite. Si inizia a pensare di utilizzare in modo libero gli spazi sulla scheda: gli spazi sulla scheda diventano i “bit” nella memoria dei nuovi ma primitivi computer e un foro diventa “1” mentre l’assenza di foro diventa “0”.
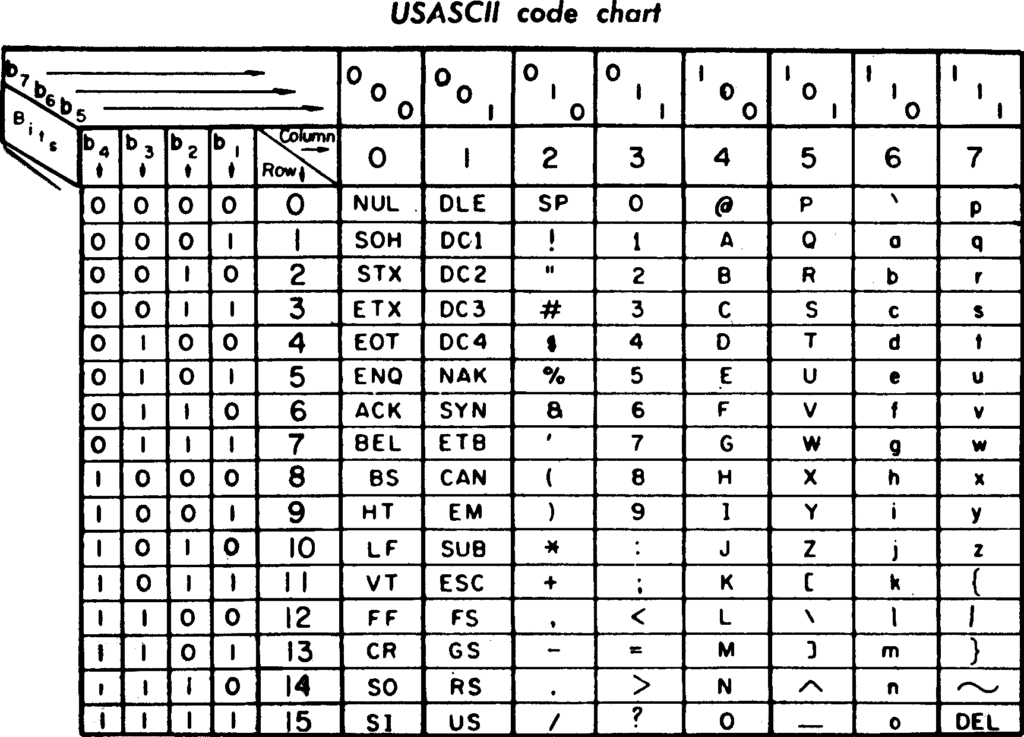
Nel 1968 l’American National Standards Institute (ANSI) pubblica quindi il Codice Standard Americano per lo Scambio di Informazioni (American Standard Code for Information Interchange, ASCII, da pronunciarsi come “askey”) che utilizza 7 bit per codificare ben 128 caratteri.
Codice US-ASCII, tratto dal manuale del TermiNet300 (1971). Wikipedia, PD.
E la nostra chiocciola? Sì, c’è! 🙂 Proprio vicino alla A maiuscola. Ha la codifica 1000000 che corrisponde al numero 64. Se vi ricordate, all’inizio di questo post, vi ho detto che potete ottenere il simbolo @ sul vostro computer anche con la combinazione di tasti Alt e 6 4 sul tastierino numero.
Infatti la codifica ASCII (e le sue evoluzioni successive) è quella tuttora utilizzata per la codifica dei caratteri nei computer… e se conoscete il codice ASCII di un carattere potete ottenerlo tenendo premuto Alt e poi digitando il codice sul vostro tastierino numero.
Fantastico, no? 😉
Promossa sul campo
Fino ad adesso la chiocciola è un simbolo che non ha nessun significato particolare nel mondo dell’informatica o delle telecomunicazioni. Anzi, in realtà, come abbiamo visto, ha un utilizzo abbastanza di nicchia, confinato negli ambienti economici, commerciali e finanziari. E questa sarà un po’ la sua fortuna… ma andiamo con ordine.
Lo scenario
Siamo negli anni sessanta.
Il mondo dei computer é molto diverso da quello che siamo abituati a vedere adesso. Possedere un computer era una prerogativa di università e grandi aziende, a causa delle dimensioni (nella migliore delle ipotesi serviva una stanza bella grande), dei costi e della professionalità necessaria. Facciamo un esempio? Questa specie di grande lavatrice è l’hard disk IBM 2311, messo in commercio a partire dal 1964.
Collegando otto di questi apparati al sistema IBM 2314 Direct Access Storage Facility si otteneva [9]IBM 2314 Direct Access Storage Facility, IBM Archives[10]Da Cruz, F. (2010, 23 agosto). A Chronology of Computing at Columbia University, Disponibile 5 febbraio, 2021 da Columbia University Computing History un disco dalla capacità di 58 Megabyte e dal costo approssimativo di 250 mila dollari.
Per darvi un’idea dei progressi, oggi un hard disk di “taglia media” si tiene comodamente in mano, ha una capacità di 2 Terabyte (pari a 2.097.152 Megabyte) e costa cinquanta euro.
Capite bene che queste “macchine” dovevano essere usate 24 ore su 24 per cercare di ammortizzarne i costi. La cosa non costituiva un problema: essendocene così poche, moltissime erano le richieste di utilizzo. Ma come fare per condividere le risorse tra molti utenti?
All’inizio, all’epoca delle schede perforate, chi voleva sfruttare un po’ della capacità di calcolo di uno di questi “mainframe” (così si chiamavano al tempo) si recava di persona sul posto e consegnava il suo mazzettino di schede (contenenti il programma da eseguire e i dati di partenza) al personale del “centro di calcolo”. La vostra richiesta, cioè le vostre schede, veniva messa in coda insieme a tutte le altre e prima o poi vi veniva restituito il risultato, un altro mazzettino di schede.
Con il progredire della tecnologia, gli ingegneri trovarono una soluzione più efficiente per permettere a utenti diversi di condividere la potenza di calcolo di un mainframe, ideando il concetto di “ripartizione di tempo”.
Gli utenti erano tutti collegati insieme e il sistema dedicava un pochino di tempo a ciascuno, a rotazione. Questo “pochino” era molto poco, ma la rotazione avveniva così velocemente che gli utenti avevano l’impressione di avere il mainframe tutto per loro.
Ma come si collegavano gli utenti? Non ci scordiamo che siamo negli anni sessanta e ancora non c’è alcun concetto di rete.
Gli utenti si collegavano con quelle che si chiamavano (e si chiamano ancora, almeno nei musei) “telescriventi”.
Telescrivente Teletype ASR-33, con tastiera, stampante e perforatore/lettore di nastro. Wikipedia, CC BY 2.0.
Erano costituite da una tastiera, dove si impartivano i comandi, e da una stampante, dove si ricevevano i risultati. Un lettore/perforatore di nastro poteva essere incluso per inserire o ricevere grosse quantità di dati. Le più “eleganti” potevano essere dotate anche di un monitor, ma la loro tecnologia era a quel tempo poco affidabile e molto costosa.
Invece la Teletype ASR-33 si diffuse a macchia d’olio proprio per il suo costo contenuto e per la sua affidabilità: in 13 anni, a partire dal 1963, ne vennero costruite oltre 600 mila esemplari.
Le telescriventi potevano essere collegate direttamente al loro mainframe con un cavo oppure attraverso una linea telefonica, consentendo un collegamento a distanza. Ma attenzione, non avevano un’intelligenza propria… erano poco più di una tastiera e di una stampante assemblate insieme.
Stanza telescriventi della TASS (Telegrafnoe Agentstvo Sovetskogo Sojuza, Agenzia Telegrafica dell’Unione Sovietica). Primi anni ’60, Mosca. rferl.org
Per questo motivo ogni telescrivente era collegata in modo permanente al suo mainframe: quindi se un ufficio aveva necessità di collegarsi a 10 mainframe diversi, doveva dotarsi di 10 telescriventi, dando luogo ad una poco confortevole (le telescriventi scrivevano continuamente e rumorosamente) “stanza telescriventi”.
Le prime email
Il problema era ben noto a Robert Taylor, informatico americano, che nel 1965 lasciò la NASA per entrare nell’ARPA (Advanced Research Projects Agency, Agenzia per progetti di ricerca avanzata), oggi nota come DARPA (Defense ARPA).
L’ARPA, lo fa anche adesso, finanziava dei progetti di università e aziende private. In particolare, l’ufficio di Taylor si occupava di seguire tre progetti diversi e quindi era necessario che si collegasse a tre mainframe. Ma facciamolo dire [11]Markoff, J. (1999, 20 dicembre). OUTLOOK 2000: TECHNOLOGY & MEDIA: TALKING THE FUTURE WITH: Robert W. Taylor; An Internet Pioneer Ponders the Next Revolution. Disponibile, 5 febbraio 2021 da The … Continue reading a lui stesso:
“We had in my office three terminals to three different programs that ARPA was supporting. One was to the Systems Development Corporation in Santa Monica. There was another terminal to the Genie Project at U.C. Berkeley. The third terminal was to the C.T.S.S. project that later became the Multics project at M.I.T.“
“Avevamo nel mio ufficio tre terminali per tre diversi programmi supportati da ARPA. Uno era alla Systems Development Corporation di Santa Monica. C’era un altro terminale per il Genie Project a U. C. Berkeley. Il terzo terminale era quello del progetto C.T.S.S., che in seguito divenne il progetto Multics, presso M.I.T.”
Attenzione, però: Taylor si trovava presso il Pentagono (in Virginia) e collegandosi al terminale del mainframe della Systems Development Corp. di Santa Monica (in California) poteva scambiare messaggi con gli altri utenti su quel mainframe, da dovunque fossero collegati.
Lo scambio di messaggi tra utenti dello stesso mainframe, anche se fisicamente distanti perché collegati ad esempio tramite telescriventi su linea telefonica, era infatti possibile [12]Kawamoto, D. (2016, 7 marzo) Creator Of Network Email Ray Tomlinson Dies. Disponibile 5 febbraio 2021, da InformationWeek sin dai primi anni sessanta grazie al programma SNDMSG. Ovviamente il sistema era molto semplice, nemmeno lontanamente paragonabile alle email di oggi: in pratica ad ogni utente, identificato univocamente da uno username (nome utente), corrispondeva un documento di testo, in cui tutti gli altri utenti potevano aggiungere righe senza leggerne il contenuto: questo documento era insomma una rudimentale inbox o “posta in entrata”.
Il vero problema consisteva nella limitazione a poter scambiare messaggi solo tra utenti dello stesso mainframe. Per il nostro Robert Taylor scrivere a diverse persone nei diversi progetti comportava spostarsi fisicamente da una telescrivente all’altra, e questo può essere realmente fastidioso anche se hai una sedia da ufficio con le rotelline 😉 E ovviamente un utente del mainframe di Santa Monica non poteva scrivere a un utente del mainframe di Berkeley. Insomma questi supercomputer, che incominciavano ad avere prestazioni migliori e dimensioni più umane, non potevano parlarsi tra loro.
ARPAnet
Robert Taylor aveva già ben presente la problematica e anche come risolverla:
“I said, oh, man, it’s obvious what to do: If you have these three terminals, there ought to be one terminal that goes anywhere you want to go where you have interactive computing. That idea is the ARPAnet. […] I decided to do that in late 1965. In February of 1966, I was officially the head of the Information Processing Techniques Office. So I went to see Charlie Herzfeld, who was the head of ARPA, and laid the idea on him. The first funding came that month. He liked the idea immediately, and he took a million dollars out of the ballistic missile defense budget and put it into my budget right then and there.“
“Ho detto, oh, amico, è ovvio cosa bisogna fare: tu hai questi tre terminali, ma dovrebbe essercene uno solo che va ovunque tu voglia andare a fare elaborazioni interattive. Quell’idea è ARPAnet. […] Ho deciso di farlo alla fine del 1965. Nel febbraio del 1966 ero ufficialmente il capo dell’Ufficio delle Tecniche di Elaborazione delle Informazioni. Così sono andato a trovare Charlie Herzfeld, che era il capo dell’ARPA, e gli ho detto l’idea. Il primo finanziamento è arrivato quel mese. L’idea gli piacque immediatamente e prese un milione di dollari dal budget della difesa contro i missili balistici e lo inserì nel mio budget in quell’esatto momento.”
E’ così che ARPAnet vede la luce, con un taglio al bilancio delle difese missilistiche americane. ARPAnet, per chi non lo sapesse, è un po’ la mamma di Internet, cioè il primo nucleo di Internet che collegava 4 centri di ricerca:
UCLA, Los Angeles
SRI, Stanford
UCSB, Santa Barbara
University of Utah, Salt Lake City
Log del IMP dell’UCLA: si nota alle 22:30 la scritta “Talked to SRI, host to host”, “Parlato con SRI, da macchina a macchina“, 29 ottobre 1969, Wikipedia, PD.
I primi 4 router (che al tempo si chiamavano IMP, Interface Message Processor, ed erano grandi come frigoriferi) si iniziarono a scambiare dati il 29 ottobre del 1969 (in particolare Los Angeles e Stanford) e formarono una rete stabile a partire dal 5 dicembre.
Nel dicembre 1970, l’anno successivo, gli IMP diventarono 13. Oltre 40 nel 1973. 213 nel 1981. Il 30 aprile 1986 arriverà anche il primo “segnale” dall’Italia, attraverso il CNUCE (Centro Nazionale Universitario di Calcolo Elettronico) del CNR di Pisa.
L’unica preposizione sulla tastiera
Ok, facciamo un passo indietro: dunque abbiamo la possibilità di scambiarci email tra utenti di uno stesso mainframe e la rete ARPAnet è nella testa di Taylor. Cosa manca per avere l’email come la conosciamo oggi? E, soprattutto, dove è finita la nostra chiocciola?
ARPA ha appena messo un milione di dollari sul piatto per la realizzazione di ARPAnet… e, essendo una agenzia statale, nel 1968 lancia un bando per il progetto. Una delle 140 aziende ad aggiudicarsi i finanziamenti [13]Ward, M. (2001, 8 ottobre) H@ppy birthday to you. Disponibile 5 febbraio 2021 da BBC News si chiama Bolt, Beranek and Newman (oggi BBN Technologies, del gruppo statunitense Raytheon).
BBN lavora attivamente alla realizzazione della rete e, nel suo staff, un giovane laureato al MIT, Ray Tomlinson, si occupa di sviluppare del software ad-hoc.
In particolare si occupa di sviluppare il programma CPYNET, un software per trasferire dei documenti da un computer ad un altro.
In passato però aveva lavorato anche al programma SNDMSG che, come abbiamo detto poco prima, serviva agli utenti di uno stesso computer per scambiarsi messaggi.
Si rese conto subito che i due programmi potevano essere in qualche modo “uniti” per ottenere qualcosa di innovativo… ma non aveva avuto un incarico specifico dai suoi capi. Ray, infatti, ricorda:
“(I did it ) mostly because it seemed like a neat idea. There was no directive to “go forth and invent email”. The ARPANET was a solution looking for a problem. A colleague suggested that I not tell my boss what I had done because email wasn’t in our statement of work. That was really said in jest because we were, after all, investigating ways in which to use the ARPANET.“
“(L’ho fatto) soprattutto perché sembrava un’idea ben congegnata. Non c’era alcuna direttiva per “andare avanti e inventare la posta elettronica”. ARPANET era una soluzione alla ricerca di un problema. Un collega mi ha suggerito di non dire al mio capo cosa avevo fatto perché l’email non era nella nostra dichiarazione di lavoro. Questo è stato davvero detto per scherzo perché, dopotutto, stavamo indagando sui modi in cui utilizzare ARPANET.”
Nel 1971, all’età di 29 anni, Tomlinson si fece la fatidica domanda [14]Tomlinson, R. (2011 Luglio). The First Email. Disponibile 5 febbraio 2021 da openmap.bbn.com… Su un computer singolo, lo username dell’utente era sufficiente per identificare il destinatario di una email… ma su ARPAnet? Sicuramente sarebbe stato necessario indicare anche il nome del mainframe dove era l’utente destinatario. Ma come separarli?
A Tomlinson serviva un carattere che non fosse presente nei nomi utente (quindi, ad esempio, il punto e il trattino non andavano bene) e ovviamente non doveva essere usato come carattere speciale nel sistema operativo che stava usando (TENEX). Quindi, ispezionando la tastiera della sua Teletype KSR-33, prese questa [15]Metz, C. (2012, 30 luglio). Meet the Man Who Put the ‘@’ in Your E-Mail. Disponibile 5 febbraio 2021 da wired.com decisione:
Of the remaining three or four characters, the ‘@’ sign made the most sense. It denoted where the user was … at. Excuse my English.
Dei restanti tre o quattro caratteri, il segno “@” era quello con più senso. Denotava “presso” quale host stava l’utente … Scusate il mio inglese.
Insomma, per Ray “@” è l’unica preposizione sulla tastiera.
Tomlinson aveva a disposizione due computer con sistema operativo TENEX che, sempre per confermare la grande fantasia degli informatici, aveva chiamato bbn-tenexa e bbn-tenexb.
I due computer fra cui venne scambiata la prima email: in primo piano bbn-tenexa, sullo sfondo bbn-tenexb; sulla sinistra si notano le due telescriventi KSR-33. Sono 2 DEC PDP-10 con processore KA10 (bbn-tenexa aveva 256 KBytes di memoria, bbn-tenexb 216 KBytes). Foto di Dan Murphy.
I due computer pur essendo uno accanto all’altro erano comunque collegati tramite ARPAnet.
In un giorno non precisato [16]Tomlinson, R. (2011 Luglio). Frequently Made Mistakes. Disponibile 5 febbraio 2021 da openmap.bbn.com della fine del 1971, Ray si sedette alla telescrivente collegata al computer bbn-tenexb e scrisse un messaggio al suo account sul computer bbn-tenexa, componendo quello che è stato il primo indirizzo di posta elettronica della storia:
tomlinson@bbn-tenexa
Ma cosa c’era scritto nella prima email? Niente di storico, niente alea iacta est, niente that’s one small step text for a man, one giant leap for mankind o roba simile. Ci viene sempre in aiuto la memoria, relativa, del nostro Ray Tomlinson:
“I have seen a number of articles both on the internet and in print stating that the first email message was “QWERTYUIOP”. ‘Taint so. My original statement was that the first email message was something like “QWERTYUIOP”. It is equally likely to have been “TESTING 1 2 3 4” or any other equally insignificant message. Apparently I didn’t hedge the statement enough because this got turned into bald statements that “QWERTYUIOP” was the the first email message. Probably the only true statements about that first email are the it was all upper case (shouted) and the content was insignificant and forgetable (hence the amnesia).“
“Ho visto numerosi articoli sia su Internet che su carta stampata affermando che il primo messaggio di posta elettronica era “QWERTYUIOP”. Non è così. La mia dichiarazione originale era che il primo messaggio di posta elettronica era qualcosa come “QWERTYUIOP”. È altrettanto probabile che sia stato “TESTING 1 2 3 4” o qualsiasi altro messaggio altrettanto insignificante. Apparentemente non ho calcato abbastanza la dichiarazione perché questa è stata trasformata in dichiarazioni spoglie che “QWERTYUIOP” era il primo messaggio di posta elettronica. Probabilmente le uniche affermazioni vere su quella prima e-mail sono che era tutto maiuscolo (gridato) e il contenuto era insignificante e dimenticabile (da qui l’amnesia).”
Un software nato così in sordina si trasforma presto in una killer app per ARPAnet: lo stesso direttore dell’Ente, Steve Lukasik, si procurò una telescrivente portatile per potersi collegare a qualsiasi nodo della rete e controllare i suoi messaggi, un’inquietante finestra aperta sul nostro presente 🙂
Solo due anni dopo, nel 1973, il 75% del traffico su ARPAnet era costituito da email.
Il resto è presente
Da qui in poi la strada della chiocciola fa parte del nostro presente.
A partire da Twitter, entra nell’utilizzo comune per identificare un utente su un social network. Molte aziende collegate al mondo dell’informatica la includono nei loro loghi.
In alcuni Paesi, come forse alcun@ di voi sapranno, viene usata anche come espressione di gender neutrality, al posto dell’asterisco.
Una cosa che forse non tutti voi sapranno, invece, è che la nostra cara chiocciola è stata “acquisita” dal MoMA (Museum of Modern Art) di New York [17]Antonelli, P. (2010, 22 marzo). @ at MoMA. Disponibile 5 febbraio 2021 da moma.org.
Ma cosa significa in pratica? Ovviamente un segno, come @, non si può acquisire, comprare come un quadro o una statua. Ma già ci sono edifici o dispositivi tecnologici (ad esempio, il Boeing 747) che sono “virtualmente” nella collezione del MoMA ma non lo sono fisicamente, per evidenti ragioni logistiche. Il segno @ é l’unico oggetto free della collezione del MoMA, ma forse è anche uno dei molti ad essere senza prezzo.
Abbiamo fatto molta strada
Come vi avevo preannunciato, la chiocciola ha una storia non irrilevante.
In questo post, partendo dai monasteri bizantini del 1300, siamo andati a caricare anfore di vino sulle navi in partenza da Cadice per il nuovo continente americano e a trasportare carichi di grano tra le province spagnole.
Abbiamo visto arrivare la nostra chiocciola sulla prima tastiera, quella di una macchina da scrivere, alla fine del 1800.
Dalle schede perforate in poi, la storia della chiocciola si lega a doppio filo con quella dell’informatica e della rete ARPAnet, su cui abbiamo fatto una, ammetto, lunga ma spero interessante digressione.
Chiudiamo purtroppo con una nota triste.
Robert Taylor, il papà di ARPAnet, e Ray Tomlinson, il “talent scout” della chiocciola, sono recentemente mancati, rispettivamente nel 2017 e nel 2016.
Ma prima di tornare al vostro lavoro, magari a cliccare freneticamente su invia/ricevi per quella email che state aspettando oppure a gestire la decina che vi attende nella vostra posta in entrata… forse potete dedicare quattro minuti della vostra vita ad ascoltare questo breve discorso di Ray Tomlinson, in occasione del suo ingresso nella Internet Hall of Fame, avvenuto il 23 aprile del 2012. E capire che, in fondo, geek si nasce, ragazzi si può rimanere anche a 71 anni, ma per diventare innovatori bisogna avere l’idea giusta al momento giusto.
Melis, F. & Cecchi, E. (1972). Documenti per la storia economica dei secoli XIII-XVI con una Nota di Paleografia Commerciale (per i secoli XIII-XVI). Firenze, Italia: Olschki
Magno, A. M. (2016, 7 marzo). Tomlinson era un grande ma-la @ l’abbiamo inventata noi italiani non lui. Disponibile 5 febbraio, 2021, da glistatigenerali.com
Markoff, J. (1999, 20 dicembre). OUTLOOK 2000: TECHNOLOGY & MEDIA: TALKING THE FUTURE WITH: Robert W. Taylor; An Internet Pioneer Ponders the Next Revolution. Disponibile, 5 febbraio 2021 da The New York Times
Dante Alighieri, “Divina Comedia”, Inferno, Canto II
Quando è stata lanciata anche in italia l’idea della app per tracciare i contatti “COVID-19” devo ammettere che il mio sopracciglio si è aggrottato… Mi sono venute in mente le problematiche relative alle analoghe soluzioni cinesi, con un complesso sistema di QR-codes che autorizzano o meno l’ingresso in un luogo e le specificità tipiche di quella nazione, dove ad esempio l’app notifica gli spostamenti non solo al Governo, ma anche alla Polizia.
L’app rilasciata ad Aprile 2020 dal governo Cinese.
La genesi
In Italia intorno al 16 aprile 2020 inizia a trapelare la notizia che il Governo ha scelto Bending Spoons per la realizzazione dell’app: è una ex-startup, fondata nel 2013, e ormai ha 140 dipendenti, 90 milioni di fatturato, una forte componente italiana e il quartier generale a Milano. E’ una delle più grandi realtà di sviluppo per ambienti mobili in Europa. Sembra uno schiaffo alle due grandi multinazionali, Apple e Google.
In realtà l’apporto dei due “Big Tech” sarà indispensabile. L’app o, meglio, tutte le app di questo tipo che sono in via di realizzazione nel mondo, hanno bisogno di gestire l’hardware (cioè i circuiti, le antenne e le componenti radio, in particolare quella BlueTooth) in una maniera molto diversa da quelle che erano state le necessità nel mondo pre-COVID-19. Vi ricordate questa scena?
Sean Connery, nei panni di Marko Ramius, nel film “Caccia a Ottobre Rosso”, 1990
L’indimenticato Sean Connery, comandante di un sommergibile russo in procinto di disertare, usa un impulso SONAR per confermare al suo antagonista americano le sue intenzioni. Cioè, sta utilizzando un sistema nato per rilevare “bersagli” come mezzo di comunicazione. Qui, invece, siamo di fronte ad una necessità opposta, ovvero utilizzare il BlueTooth, uno standard di comunicazione (solitamente usato per collegare cuffiette, casse e altri accessori) per rilevare altri terminali nelle vicinanze. Purtroppo nessuno aveva ancora pensato a costruire uno smartphone con un RADAR a bordo. Ancora. Non vi prometto nulla per il futuro… 😉
I due colossi di Mountain View e Cupertino (a proposito, lo sapevate che i quartier generali di Google e Apple distano tra loro solo 12 minuti in auto?) sono già sul pezzo, non vi preoccupate. Il 10 aprile, cioè circa una settimana prima delle notizie su Bending Spoons di cui abbiamo parlato, Apple e Google annunciano un progetto congiunto per rilasciare una serie di API pensate allo scopo.
Ma cosa sono queste API (Application Programming Interface)? Scegliete un’app qualsiasi sul vostro smartphone. Essa non gestisce direttamente l’hardware del telefono. Pensate alla complessità se ogni app dovesse gestire l’hardware (schermo, batteria, antenne, pulsanti, ecc.), sempre diverso, di tutte le migliaia di modelli che sono stati messi in commercio. Tutte le app utilizzano per la gestione dell’hardware delle procedure, che chiameremo interfacce, standard e sempre uguali (prendete quel “sempre” cum grano salis) messe a disposizione da chi produce il telefonino stesso. Le API, appunto.
Come dicevo, queste API sono essenziali per permettere a tutte app di tracciamento dei contatti di utilizzare l’hardware (in particolare il BlueTooth) in una maniera che, in un mondo pre-COVID-19, nessuno aveva immaginato.
E dopo due mesi di lavoro, il 1 giugno, il Ministero della Salute annuncia che Immuni ha emesso il primo vagito ed è disponibile sugli store Apple e Google. Un attimo: cosa c’entra il Ministero della Salute? Il Ministero è a tutti gli effetti il proprietario (o, meglio, sviluppatore) “ufficiale” dell’app. Inoltre, all’inizio di ottobre 2020 Bending Spoons, dopo aver realizzato a titolo gratuito l’app, ha “passato le consegne” a Sogei e PagoPA, i due “bracci” informatici dello Stato Italiano.
A cosa serve?
Come abbiamo detto l’app è dedicata al contact tracing o, meglio, al tracciamento dei contatti.
L’attività di tracciamento dei contatti è di solito fatta dal personale della sanità pubblica e, nel caso di una malattia con una asintomaticità elevata o comunque con un periodo di incubazione, è essenziale. Se non ci fosse il tracciamento dei contatti, una persona asintomatica o in incubazione riuscirebbe ad infettare molte persone prima di, rispettivamente, guarire o di mostrare i sintomi e quindi essere diagnosticata ed isolata.
Il personale che effettua il tracciamento dei contatti “intervista” ogni persona con una diagnosi accertata di COVID-19 e avverte tutte le persone che sono entrate in contatto con essa. Queste ultime dovranno quindi isolarsi preventivamente e verificare se sono state infettate.
Scene di “contact tracing” dal film Contagion (2011). Qui si vedono soprattutto ricostruzioni dei contatti effettuate post-mortem dell’infetto.
Quindi con un sistema di tracciamento dei contatti efficiente si isolano tutti i potenziali contagiati prima che possano trasmettere il virus SARS-CoV-2, inconsapevolmente, a qualche altra persona. Più in generale, con un buon tracciamento dei contatti, ogni infetto trasmette il virus a meno persone rispetto ad una situazione in cui il tracciamento dei contatti è fatto male o assente.
Il numero medio di persone a cui ogni infetto trasmette il virus si chiama indice di trasmissione, per gli amici Rt: una sigla che avrete spesso sentito nelle notizie di questi mesi. Un Rt maggiore di uno (ovvero se ogni persona contagia a sua volta più di una persona) comporta una crescita cosiddetta “esponenziale” del numero di infetti. E’ molto importante quindi che il tracciamento sia veloce, efficiente e efficace allo scopo di mantenere l’indice Rt più basso possibile.
E’ abbastanza evidente che questa attività ha diversi punti critici:
richiede un rilevante impegno di tempo per intervistare l’infetto e successivamente avvertire tutti le persone che sono venute in contatto con lui;
richiede che l’infetto conosca e si ricordi l’identità di tutti i contatti di cui al punto precedente, cosa di solito impossibile nel caso di permanenza in locali, mezzi di trasporto pubblico, ecc.;
la persona infetta potrebbe essere restìa a comunicare le persone con cui è venuta a contatto per motivi di riservatezza.
Ed è qui che entra in gioco l’app, risolvendo tutte e tre le criticità che abbiamo appena evidenziato:
l’attività di notifica ai contatti è automatica e immediata, solo la certificazione dello stato di positività viene mediata da personale sanitario
non richiede lo sforzo di memoria da parte dell’infetto, i suoi contatti sono memorizzati in modo anonimo dallo smartphone
la privacy è salvaguardata in modo assoluto (… eh, sì, ne parleremo dopo)
Come funziona?
Ma come funziona in pratica l’app Immuni? Se siete interessati, e se state leggendo immagino che lo siate, si trovano filmati e guide fatte benissimo, con grandi risorse di grafica. Primo fra tutti il sito ufficiale Immuni, che vi consiglio di visitare soprattutto per scaricare l’app, se non l’avete ancora fatto.
Io tenterò un approccio diverso. Mi sono fatto questa domanda: se questa pandemia fosse accaduta 20 o 30 anni fa, quando gli smartphone non esistevano, come si sarebbe potuto realizzare un sistema analogo ma “analogico”, perdonatemi l’assonanza delle parole?
Come sappiamo il primo passo oggi è quello di installare l’app. In un mondo pre-digitale ci saremmo rivolti invece a un negozio, probabilmente un tabaccaio e avremmo acquistato (o, più probabilmente, ci sarebbe stato dato gratuitamente) un Kit Immuni, un cofanetto sigillato e assolutamente anonimo.
Complimenti, ecco il vostro nuovo Kit Immuni!
Cosa avremmo trovato al suo interno?
un manuale d’uso
un biglietto filigranato con un numero casuale X e alcuni codici di controllo, molto simile a quello della lotteria di fine anno
una grande quantità (alcune migliaia) di biglietti da visita: biglietti fatti in un materiale magico “antivirale”, consentitemi questo volo di fantasia (non sarà l’unico, vedrete), e completamente bianchi, se non in un piccolo riquadro dove ci sarà lo stesso numero X di cui parlavamo sopra, coperto da una patina tipo “gratta-e-vinci”.
Vi risparmierò ora la fatica di leggere il manuale e vi guiderò passo passo nell’utilizzo quotidiano, non preoccupatevi! 😉
Innanzitutto, prendete il vostro biglietto filigranato e mettetelo in un posto sicuro. Questo sarà il vostro numero, vi identificherà, ma notate bene: nessuno sa che vi è stato assegnato questo specifico numero, infatti tutti i cofanetti sono anonimi e non è possibile rintracciare il numero inserito all’interno e soprattutto da chi è stato acquistato.
Ok, quindi, mettetevi adesso una manciata di quei strani biglietti da visita in tasca e uscite. Da qui in poi dovrete tenere d’occhio tutte le persone che vi girano attorno, amici, parenti e sconosciuti, sul posto di lavoro e sui mezzi pubblici. Ho detto tenere d’occhio, ma in realtà più che l’occhio vi saranno utili un cronometro e un metro… già, perché se una persona si avvicinerà a voi per più di 15 minuti a meno di due metri dovrete dargli un vostro “biglietto da visita” e lui dovrà dare il suo a voi: supponiamo infatti, altro volo di fantasia, di essere in un mondo ideale dove tutti hanno a cuore la propria salute (e quella degli altri) e quindi tutti si sono dotati del loro Kit Immuni.
Ovviamente questa cosa dovrà essere fatta nel modo più anonimo possibile, e infatti c’è chi dice che nel secondo lotto di Kit Immuni che verrà messo in commercio ci sarà anche un passamontagna da indossare durante lo scambio… 😉 C’è da dire che indossare la mascherina aiuta a mantenere l’anonimato perché, ovviamente, utilizzare il Kit Immuni non esonera da tutte le normali precauzioni e regole.
Alla fine della giornata, quando tornerete a casa, vi troverete in tasca un mazzetto di biglietti da visita, non riconducibili a nessuna persona. Prendere tutti questi biglietti (ipotizziamo dieci) e metteteli, uno sopra l’altro, su una mensola. Se usate il vostro Kit Immuni già da un po’ avrete diversi mazzetti, uno accanto all’altro, uno per giorno. Se ne avete più di 14, buttate via i più vecchi: se siete precisi e metodici, questo vuol dire buttare via, ogni giorno, il 15mo mazzetto.
A questo punto, innanzitutto incominciate a grattare e scoprire i codici dei dieci biglietti di oggi. Immaginiamo che abbiate una vita piuttosto regolare e che ogni giorno raccogliate 10 nuovi biglietti dalle persone che incontrate. Sempre per semplicità, immaginiamo che incontriate persone sempre diverse.
Quindi adesso avrete sulla mensola 140 biglietti con, in totale, 140 codici diversi.
Non vi resta che sintonizzarvi sulla TV e assistere al nuovo show “Covid-Lotto”, dove tutte le sere vengono letti i codici dei positivi. Chi ha riceve la diagnosi di positività al virus, infatti, comunica il suo numero identificativo al “call-center” Immuni, il quale provvede a verificarlo con i codici di controllo e a metterlo nella lista di questo nuovo “lotto”.
Con i numeri di novembre 2020, si tratta di ascoltare qualche decina di migliaia di numeri estratti con 140 biglietti da controllare. Rimpiangete già la tombola natalizia, eh? 😉
Montiamo a bordo della nostra DeLorean e torniamo nell’anno di grazia 2020, adesso. Molti di voi avranno già capito le analogie di questo “esercizio di stile” con l’app Immuni. Il biglietto della “lotteria” è il codice pseudo-casuale che viene generato quando viene installata l’app. I biglietti da visita sono i “messaggi” che i telefoni si scambiano in automatico.
E, fortunatamente, la tecnologia ci permette oggi di fare cose più sofisticare come, ad esempio, cambiare il codice ogni 10 minuti per incrementare la tutela della privacy oppure consentire ai telefonini di scambiarsi informazioni sulla data e ora del contatto e la distanza, per fare delle rilevazioni più precise.
Ma la privacy è a rischio?
La principale questione che riguarda Immuni, e tutte le altre app per il contact tracing (già perché ogni Paese ne ha una diversa, anche se recentemente sono stati fatti dei passi in avanti in tal senso), è la riservatezza delle informazioni che vengono raccolte. Informazioni che, ovviamente, riguardando la salute, sono tra quelle considerate “sensibili”.
Cosa condividiamo?
Per capire le implicazioni sulla privacy di qualsiasi cosa, sia essa un’app, una procedura o un nostro collaboratore, dobbiamo capire quale sono le informazioni a cui ha accesso.
Abbiamo già detto che gli identificativi che le app Immuni si scambiano sono dei codici casuali che non permettono di risalire al proprietario dello smartphone.
Inoltre quelli di voi che hanno già installato Immuni sapranno che, contrariamente a quasi tutte le altre app, essa non richiede la creazione di un account: questo vuol dire che la vostra app Immuni non è associata ad alcun dato che vi possa identificare, come ad esempio l’indirizzo di posta elettronica o il numero di cellulare. Questo è possibile perché Immuni conserva tutte le sue informazioni sul telefonino dove è installata e non in qualche server remoto.
Sono ben poche le app che hanno lo stesso approccio: molte infatti, anzi, quasi tutte, richiedono di effettuare una procedura chiamata “registrazione” o, per lo meno, di verificare il vostro numero di telefono. Immuni chiede invece solo la provincia di residenza, per poter raccogliere dei dati epidemiologici significativi.
Ma di tutte le informazioni che sono disponibili su uno smartphone, quali sono quelle accessibili all’app Immuni? Tutte le app, non solo Immuni, “chiedono” di poter utilizzare le informazioni (le foto, la rubrica, …) e le risorse hardware (il microfono, la fotocamera, …) a cui vogliono accedere. Il sistema operativo dello smartphone (ovvero quello che noi chiamiamo Android o iOS) si occupa di controllare che le app si attengano a quello che hanno richiesto; in alcuni casi, subito dopo la prima installazione o durante il primo utilizzo, chiedono anche conferma all’utente.
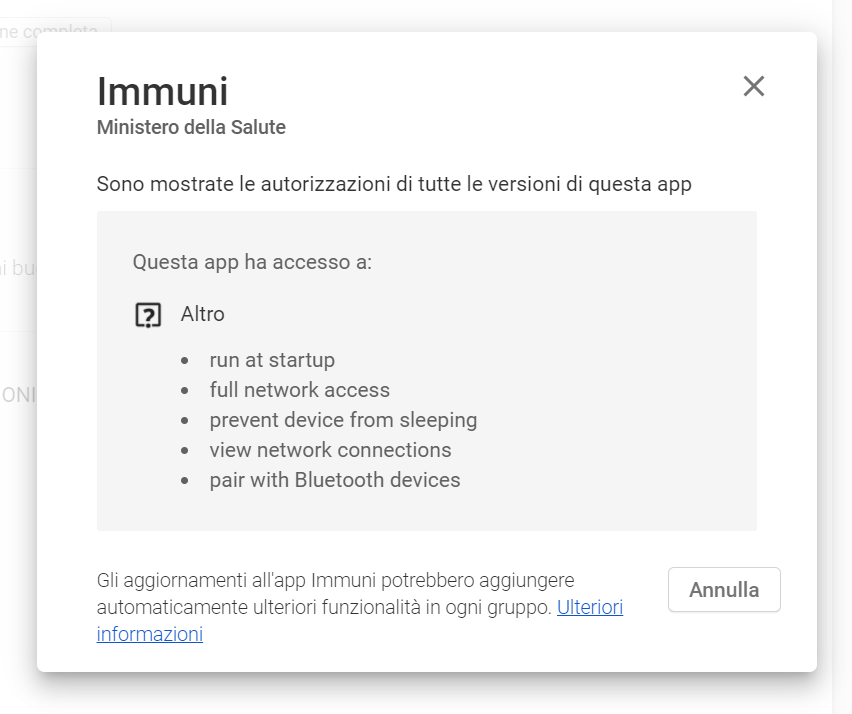
Vediamo ora quali sono le “autorizzazioni” o “permessi” richiesti dall’app Immuni; qui di seguito analizzerò per brevità solo la versione Android, ovviamente le stesse cose valgono per l’app iOS.
I permessi richiesti dall’app Immuni android alla versione 2.1.1 del 3 novembre 2020
I permessi si possono trovare nella sezione Impostazioni del vostro smartphone; qui, per semplicità, mostro la pagina relativa all’app Immuni sul Play Store di Google (il link è nella didascalia).
Vedete che l’app chiede cinque permessi, traduciamo dall’inglese:
avviarsi automaticamente quando si accende lo smartphone: mi sembra ragionevole, è necessario che sia sempre attiva per svolgere il suo lavoro correttamente… e se volessimo spegnerla possiamo sempre farlo esplicitamente (ma perché?)
accesso pieno alla rete: Immuni ha bisogno di scaricare giornalmente i codici degli “infetti” per confrontarli con quelli raccolti durante la sua attività di monitoraggio, quindi è necessario che abbia accesso a internet;
impedire che il dispositivo vada in “risparmio energetico”: alcuni telefoni utilizzano la batteria in modo molto parsimonioso e quando l’utente non li sta utilizzando spengono quasi tutte le loro funzionalità… questo ha comportato, nelle prime versioni di Immuni, anche alcuni malfunzionamenti e blocchi dell’applicazione. Con le nuove versioni e grazie ad aggiornamenti rilasciati dalle aziende che producono smartphone, la funzionalità di Immuni è salvaguardata senza compromettere la durata della batteria;
vedere le connessioni di rete: questo permesso fa il paio con l’accesso pieno alla rete, per avere visibilità delle connessioni disponibili;
comunicare con altri dispositivi BlueTooth: questo ovviamente è essenziale per consentire ad Immuni di scambiarsi i codici con gli altri telefonini.
Troppi permessi? Pochi? Difficile avere un’idea precisa così in assoluto. Forse dovremmo confrontarlo con altre app molto più diffuse e che ci siamo abituati ad avere da lungo tempo tra le nostre icone.
Prendiamo ad esempio WhatsApp. Ormai un prodotto della famiglia Zuckerberg (leggi Facebook), la prima versione risale al febbraio del 2009. Ha ben 2 miliardi di utenti attivi (dati Statista 2020). WhatsApp ha quarantadue permessi, inclusi tutti quelli di Immuni.
Rimaniamo appunto in famiglia… Facebook. Richiede quarantacinque permessi per funzionare.
Sia WhatsApp che Facebook hanno ad esempio pieno accesso alla localizzazione dello smartphone via satellite, leggere e modificare i vostri contatti della rubrica, accedere alla fotocamera e al microfono, e tanto altro. E questa differenza non è sicuramente la più rilevante.
Come lo condividiamo?
Abbiamo visto le informazioni e le risorse hardware a cui ha accesso l’app Immuni sono quantitativamente molto ridotte rispetto a quelle a cui hanno accesso altre app molto più “tollerate” dall’opinione pubblica.
Ma cosa fanno le app con le informazioni a cui hanno accesso? Possiamo rispondere a questa domanda da due punti di vista, uno legale e uno tecnologico.
Iniziamo dal primo punto di vista, meno vicino alle mie corde, lo ammetto. L’app Immuni evidenzia in modo chiaro alcuni punti riguardanti la privacy:
-) I dati salvati sul tuo smartphone e le connessioni tra
l’app e il server sono cifrati.
-) Tutti i dati salvati sul dispositivo o sul server saranno
cancellati quando non più necessari e in ogni caso prima
del 31 dicembre 2020.
-) I tuoi dati sono raccolti dal Ministero della Salute e
verranno usati solo per contenere l’epidemia del Covid-19
o ai fini della ricerca scientifica.
-) I dati sono salvati su server in Italia e gestiti da
soggetti pubblici.
Sebbene il primo punto sia abbastanza comune tra tutte le app moderne, gli altri sono abbastanza “peculiari”. Leggiamo invece un estratto delle Condizioni d’uso di Facebook.
...quando l'utente condivide, pubblica o carica un
contenuto protetto da diritti di proprietà intellettuale
in relazione o in connessione con i Prodotti di Facebook,
concede una licenza non esclusiva, trasferibile,
sub-licenziabile, non soggetta a royalty e valida in
tutto il mondo per la trasmissione, l'uso, la
distribuzione, la modifica, l'esecuzione, la copia, la
pubblica esecuzione o la visualizzazione, la traduzione
e la creazione di opere derivate dei propri contenuti
(nel rispetto della privacy e delle impostazioni dell'app
dell'utente). Ciò implica, ad esempio, che se l'utente
condivide una foto su Facebook, autorizza Facebook a
memorizzarla, copiarla e condividerla con altri soggetti
(sempre nel rispetto delle proprie impostazioni), quali
i fornitori di servizi che supportano il servizio o gli
altri Prodotti di Facebook che l’utente usa.
Quando noi carichiamo un contenuto, diamo a Facebook il permesso di utilizzarlo in qualsiasi modo e di concedere ad altri lo stesso permesso (“sub-licenziabile”), solamente facendo salve le impostazioni di privacy impostate dall’utente.
Anche se non siete particolarmente portati per la giurisprudenza, potete capire che l’approccio è fondamentalmente diverso.
Veniamo adesso al secondo punto di vista, ovvero cerchiamo di capire come si comportano le app relativamente alla gestione delle informazioni, con un approccio più tecnico. Questo aspetto, per la maggior parte delle app che abbiamo sullo smartphone, è non determinato. Sarò più chiaro: cosa fanno la maggior parte delle app con le informazioni a cui hanno accesso? Non lo sappiamo. Certo, possiamo fare delle indagini, sia sull’app che sui dati che essa scambia con i suoi server di riferimento ma, in generale, essendo sia l’app che il traffico in un formato non comprensibile all’essere umano, è molto difficile.
Infatti, sebbene il traffico sia criptato anche per tutelare la nostra privacy, tutte le app vengono fornite agli smartphone in un formato non “intellegibile” da un essere umano, ma facilmente “digeribile” da un processore elettronico. Infatti quello che i programmatori scrivono in un linguaggio formale e comprensibile agli occhi umani (chiamato codice sorgente) e che, successivamente, dà origine all’app vera e propria, è molto spesso un segreto industriale conservato molto gelosamente, proprio perché contiene la logica con cui un’app funziona. La cosa non vale per Immuni. Il codice sorgente delle app Android e iOS di Immuni è infatti, come si dice in gergo, aperto. Tutti possono vedere e comprendere (per la comprensione ovviamente sono richieste delle competenze di programmazione) come funzionano le app, quali dati si scambiano e in che occasioni.
Non solo, tutti possono anche individuare difetti e malfunzionamenti (eh sì, tutti i programmi ne hanno, essendo realizzati da persone) e proporre correzioni e miglioramenti, tutto con discussioni pubbliche; ne vedremo dopo alcuni esempi.
Quindi possiamo dire con ragionevole certezza quello che fa Immuni con i dati a cui ha accesso. Concentriamoci ovviamente sulle informazioni che transitano dal nostro smartphone verso i server di Immuni.
Il caricamento del nostro codice “segreto” (univoco, ma che non permette di risalire alla nostra identità) sui server di Immuni avviene solo in un caso ben definito: ovvero se veniamo trovati positivi al COVID.
In questo modo tutte le altre app se lo scaricheranno e potranno verificare se vi hanno “incontrato” ovvero se il vostro codice corrisponde con uno di quelli che hanno memorizzato nelle loro ultime 14 giornate. Questa procedura deve essere autorizzata dall’operatore sanitario che ha riscontrato la positività, attraverso un codice di controllo, per evitare che utenti maldestri o malintenzionati possano segnalare positività non veritiere.
Inoltre l’app Immuni, come tutte le app, raccoglie e invia ai suoi server di riferimento un certo numero di parametri di funzionamento. Queste informazioni sono dette “analytics” e sono essenziali ai fini di verificare il corretto funzionamento dell’infrastruttura e di estrarre statistiche epidemiologiche, come quelle riportate in questa pagina web. Ovviamente gli analytics sono raccolti in modo assolutamente anonimizzato e non potrebbe essere altrimenti, visto che l’app non ha alcun modo, come abbiamo ripetuto diverse volte ormai, di accedere alla reale identità dell’utente. Per chi conosce l’inglese, qui è disponibile un elenco di tutte le informazioni raccolte.
Le scuse
Ma quali sono le ragioni, o meglio scuse, per cui non si installa Immuni?
Non mi occuperò di questioni politiche, se non dicendo che è indegno di un paese civile che i mezzi per contrastare una pandemia (non solo l’app Immuni, purtroppo) diventino oggetto di propaganda e polemica politica.
Mi auguro che questo lungo post sia stato sufficiente a illustrarvi come Immuni è l’ultima app che può mettere a repentaglio la vostra privacy. Molte altre app, ma anche lo stesso smartphone, sono invece una vera miniera di informazioni per chi le sa estrarre. Ma questo, magari, sarà oggetto di un altro post 🙂
Da quello che sento in giro, invece, molte persone temono di essere bloccate da un cosiddetto “falso positivo”. Con “falso positivo” si intende un errore tipico di un qualsiasi sistema di rilevamento, ovvero quando viene rilevata una situazione “di interesse” (in questo caso la positività al virus) ma questa situazione non corrisponde al vero. Pensiamo ad un caso pratico: noi restiamo in una sala d’attesa per circa 30 minuti in uno studio professionale; nel frattempo, nello studio medico accanto (completamente indipendente e con diverso ingresso), una persona infettiva che magari verrà diagnosticata tra una settimana, rimane anche lei in attesa per gli stessi 30 minuti. C’è un muro che ci separa, quindi non c’è possibilità di contaminazione da droplets. Ma, purtroppo, quel muro è una parete in cartongesso che consente comunque agli smartphone di scambiarsi i codici. E quindi queste due persone risulteranno “contatti stretti” anche senza mai essere state nello stesso ambiente.
Dobbiamo però chiarire alcune cose.
Supponiamo di aver ricevuto la notifica di contatto con una persona positiva. La notifica in realtà non è stata “ricevuta”, nel senso che è lo smartphone stesso a rilevare il contatto e a comunicare la cosa all’utente attraverso la visualizzazione sullo schermo. Quindi, nessuno sa che effettivamente ci è stato notificato il contatto.
Infatti la notifica stessa invita a prendere eventualmente contatto con il vostro medico di medicina generale per comunicargli la cosa e nessuno potrà mai chiedervi conto di una “rilevazione di esposizione a rischio” a cui non avete dato seguito.
Ovviamente, il principio di precauzione, spesso invocato a sproposito nella nostra società, in questo caso dovrebbe essere invece tenuto in considerazione. Siete proprio sicuri che quel contatto rilevato dall’app Immuni sia stato un “falso positivo”? Era la persona nello studio medico accanto al vostro che non avete nemmeno avuto occasione di vedere oppure qualcuno sull’autobus a cui magari non avete fatto caso? Siete pronti a scommetterci sopra la salute delle altre persone, magari vostri cari, che potreste contagiare? Una vita o più perse per sempre contro 14 giorni di isolamento.
Ne vale veramente la pena?
E’ tutto perfetto?
Insomma, è tutto a posto. L’app Immuni è perfetta. No, sappiamo che non lo è.
Anche se non fosse intervenuta la trasmissione televisiva Report (con un paio di servizi, l’ultimo dei quali potete trovare a questo link) sappiamo che ci sono alcuni problemi, raggruppabili in tre categorie:
problemi tecnologici, come vulnerabilità, malfunzionamenti, limitazioni dovute alle tecnologie utilizzate e incompatibilità con i terminali più vecchi;
il ruolo di Google e Apple nella gestione dell’hardware e delle informazioni;
le interazioni con il Servizio Sanitario Nazionale.
Problemi
Partiamo dall’inizio, cioè da una cosa che avevamo evidenziato all’inizio di questo post.
Limiti della tecnologia
La tecnologia su cui si basa Immuni è il BlueTooth. Un protocollo di comunicazione che è stato “riadattato” a funzionare come una specie di RADAR… E’ stato usato il BlueTooth perché praticamente presente su tutti gli smartphone recenti e perché lavora nell’intervallo di distanza corretto: un dispositivo BlueTooth di classe 2, quella maggiormente diffusa sui telefonini, arriva infatti al massimo a 10 metri di distanza in campo libero, evitando quindi di poter rilevare altri dispositivi a distanza maggiore, che sarebbero assolutamente non importanti ai fini epidemiologici. Purtroppo il comportamento del segnale radio BlueTooth non è così prevedibile in ambienti chiusi, specialmente quelli con strutture metalliche, come, ad esempio, mezzi di trasporto. Ma, come abbiamo già evidenziato, abbiamo solo questa arma a disposizione e dobbiamo quindi far di necessità virtù.
La gestione particolare del BlueTooth e i nuovi sviluppi fatti da Google Apple per renderla possibile richiedono inoltre due requisiti:
un BlueTooth a basso consumo energetico, detto BLE (BlueTooth Low Energy)
un sistema operativo non eccessivamente vecchio
Per Apple questo è facilmente verificabile, in quanto esiste un solo produttore e una sola linea di telefoni. L’iPhone più recente su cui non è possibile installare Immuni è l’iPhone 6, presentato nell’ormai lontano settembre 2014. Gli iPhone 6S e SE (e i modelli più recenti) invece lo supportano. Per Android la cosa è più complicata, in quanto le politiche di aggiornamento dei vari terminali dipendono dai costruttori. Oltre al BLE è necessario un sistema operativo almeno versione 6 (chiamato amichevolmente “Marshmallow”): per conoscere la versione aprite questo link dal vostro telefonino. Purtroppo i terminali Huawei, in teoria, sarebbero tagliati fuori per il noto “ban” imposto dall’amministrazione (ormai uscente) USA che impedisce loro di avvalersi dei Google Play Services, un componente software alla base di molti servizi forniti dal colosso di Mountain View. In realtà il ban non consente a Huawei di preinstallare tale componente ma, nella maggior parte dei casi, non impedisce all’utente di installarlo dopo l’acquisto, in modo più o meno complicato. Il problema è quindi aggirato.
Bug e vulnerabilità
Ogni prodotto software, come l’app Immuni, é soggetto a delle problematiche a causa di un peccato originale:
gli sviluppatori, ovvero coloro che scrivono il software, sono esseri umani e tutti gli esseri umani, scrivente incluso, hanno la peculiare caratteristica di commettere errori.
Questi errori, in un software, nella maggior parte dei casi creano malfunzionamenti generici più o meno gravi, che in gergo si chiamano bug. In altri casi, permettono ad altri esseri umani di approfittarsene e di costringere il software a comportarsi in maniera per loro vantaggiosa… siamo di fronte, in questo caso, a delle vulnerabilità.
Bug e vulnerabilità di Immuni vengono pubblicati in maniera “aperta”, così come abbiamo detto per il codice sorgente. Potete vedere qui quelli dell’app iOS e qui quelli dell’app Android. In questo momento, mentre sto scrivendo, ne esistono circa un’ottantina ancora non risolti. Gli aggiornamenti più o meno frequenti delle app servono proprio a questo, ovvero a fornirvi una nuova app con meno bug e vulnerabilità rispetto alla precedente. O almeno si spera 😉
Uno dei bug più importanti ha riguardato la versione Android dell’app, su un numero limitato, ma ancora non ben chiaro, di modelli: in particolare alcuni dispositivi Huawei e Samsung. La notizia è trapelata sugli organi di informazione intorno alla metà di settembre 2020. Questi smartphone non hanno effettuato lo scaricamento giornaliero dei codici segreti degli utenti positivi dai server Immuni per circa 10-15 giorni, con un danno rilevante all’efficacia del tracciamento dei contatti. Il problema è stato limitato nel tempo ed è stato comunque pubblicato un aggiornamento per evitare il ripetersi del problema. Dopo un paio di settimane è inoltre emerso un problema di minore entità anche sull’app iOS, causato da un aggiornamento del sistema operativo di Apple.
Parliamo ora delle vulnerabilità.
L’ormai già citata puntata di Report ha portato alla luce della ribalta una vulnerabilità detta “Replay Attack“. Non c’era nulla di nascosto ovviamente, la discussione è aperta, pubblica e anche piuttosto accesa. Se avete tempo potete divertirvi leggendo qui e qui. Ma come funziona? E su cosa si basa? Purtroppo, come abbiamo detto, il protocollo utilizzato (BlueTooth Low Energy) è stato scelto a causa della sua diffusione capillare, non per la sua sicurezza.
Semplificando un po’, è possibile che un utente malintenzionato faccia una raccolta dei codici segreti che vengono scambiati in un luogo e poi li ritrasmetta in un altro posto. Ipotizziamo, ad esempio, che il nostro hacker metta uno “sniffer”, ovvero un apparato dedicato solo a ricevere e a salvare codici, vicino ad un ingresso di un ospedale, quindi con un’alta probabilità che poi qualche codice si riveli appartenere a un positivo. Mettiamo che poi questi codici vengano ritrasmessi (“replay”) in un posto particolarmente affollato o di grande passaggio, uno stadio, ad esempio. Le app Immuni delle persone nello stadio riceveranno tutti questi codici e li registreranno come contatti… contatti che in realtà non sono mai avvenuti. Contatti che potrebbero trasformarsi di esposizioni a rischio se una quota di questi codici si rivelasse appartenente a persone positive.
Lo scopo di tutto ciò? Generare finte esposizioni a rischio porterebbero un numero molto alto di persone “fintamente esposte” a rivolgersi alle strutture sanitarie, mettendole ancora più in crisi. Consideriamolo dunque alla stregua di un attacco terroristico.
Questo in teoria. In pratica la realizzazione di questo attacco non è così semplice. I codici trasmessi contengono anche un riferimento temporale, quindi o sono trasmessi in tempo reale dall’ospedale allo stadio (cosa non semplicissima) oppure bisogna retrodatare gli orologi degli smartphone bersaglio… fattibile, ma molto difficile farlo su grandi numeri. Una vulnerabilità quindi esiste, ma è molto difficile sfruttarla ottenendo risultati eclatanti.
Come diceva un tale,
un computer spento e chiuso in una cassaforte è il sistema più sicuro del mondo ma, purtroppo, completamente inutile.
Detto in modo più rigoroso, ogni sistema informatico è un equilibrio più o meno bilanciato tra sicurezza e usabilità.
Google e Apple, sempre loro
All’inizio di questo post abbiamo parlato delle API sviluppate da Google e Apple per la gestione del BlueTooth nelle app di tracciamento dei contatti.
Queste API si sono evolute in un sistema più evoluto chiamato Google/Apple Exposure Notification (GAEN) system, con miglioramenti relativi alla sicurezza e con maggiori funzionalità. Addirittura, a partire da settembre 2020, è stato creato un sistema chiamato Exposure Notifications Express dedicato agli Stati che non possono permettersi o non vogliono occuparsi in prima persona dello sviluppo di un app di contact tracing.
Google e Apple mettono a disposizione un sistema di tracciamento “chiavi in mano”:
le autorità sanitarie definiscono la grafica e il nome dell’app, alcuni parametri epidemiologici e si occupano dei server per la gestione dei dati;
Google e Apple si occupano di tutto il resto, con due modalità diverse:
Google crea in automatico un’app dedicata, da caricare sul Play Store, con codice sorgente aperto;
Apple integra le funzionalità nel suo sistema operativo iOS, quindi l’utente non dovrà nemmeno scaricare l’app.
Tutto questo pone comunque una questione.
Come avrete capito questo sistema di gestione della notifica delle esposizioni Google/Apple è un “pezzo” di software necessario. Ci sono dei sistemi analoghi (il protocollo DP-3T e il protocollo TCN, ad esempio) ma il sistema GAEN è l’unico che viene realizzato a livello di sistema operativo e che quindi garantisce, soprattutto per i telefoni Apple, un funzionamento affidabile.
Google e Apple hanno quindi praticamente accesso a tutti i dati che vengono trasmessi dalle app come Immuni (inclusa Immuni). Ma c’è da preoccuparsi? I due hanno accesso già a molte altre informazioni, praticamente tutte quelle che passano sui nostri terminali. Localizzazione, dati biometrici, sensori (microfono, fotocamera), informazioni, foto, documenti, sms. Insomma se vi preoccupate della riservatezza e temete in particolare queste due multinazionali, forse è meglio che non utilizziate uno smartphone. Se invece già ne possedete uno, installare Immuni non cambierà sostanzialmente la situazione.
Il collegamento con il SSN
Veniamo dunque al nostro Sistema Sanitario Nazionale e, in particolare, al suo interfacciamento con l’app Immuni.
Abbiamo già visto che le situazioni in cui l’app chiede di trasmettere informazioni al SSN sono due:
nel caso l’utente sia rilevato positivo, esso deve notificare all’operatore sanitario che utilizza Immuni: si avvia quindi la procedura di autorizzazione al caricamento del codice segreto dell’utente nella lista dei codici “positivi”;
nel caso l’utente sia notificato di un’esposizione a rischio, esso deve contattare il Medico di Medicina Generale
E’ evidente che se l’utente non agisce in modo “corretto”, ovvero come descritto qui sopra, l’app Immuni viene tagliata fuori, viene resa inutile. Sfortunatamente lo può fare senza rischiare nulla, visto che nessuno può sapere che l’utente infetto sta usando Immuni, né che l’utente al momento sano ha ricevuto una notifica di esposizione a rischio.
Vediamo adesso come questo non sia proprio un caso ipotetico. Consideriamo l’interazione del primo tipo, ovvero il caricamento del codice sui server di Immuni da parte degli utenti dell’app che vengono rilevati positivi al SARS-CoV-2. Dalla dashboard di Immuni si evince che la percentuale di download in Italia, facendo una media tra i dati regionali, è del 19,8%. Un dato già scandaloso di suo, ma il bello deve ancora venire. Parliamo di download, quindi non è detto che chi la scarica poi la usi e la continui ad usare. Ipotizziamo che la metà, il 10%, sia un utente abituale. Cioè supponiamo che il 10% degli italiani usi abitualmente Immuni, un’ipotesi molto cautelativa. Analizziamo, per esempio, i primi 15 giorni di novembre. Prendiamo i dati dei nuovi infetti per singolo giorno così come diffusi dal Dipartimento della Protezione Civile e i dati relativi all’app Immuni, pubblici, in particolare il numero di utenti che giornalmente pubblicano il loro codice segreto perché diagnosticati positivi. Per quanto fin qui detto, ci potremmo aspettare che per ogni 100 nuovi infetti, 10 codici di utenti positivi vengano caricati sui server di Immuni, ovvero una percentuale del 10%.
Come vediamo la percentuale dei codici caricati è decisamente inferiore, in media 20 volte inferiore.
Solo il 5% degli utenti Immuni diagnosticati positivi al virus pubblica il proprio codice
Qualcuno potrà ipotizzare che i contagiati siano soprattutto persone anziane, quindi meno avvezze all’utilizzo della tecnologia. In realtà, dai dati di Epicentro, portale dell’Istituto Superiore di Sanità, negli ultimi 30 giorni circa il 55% dei contagiati ha meno di 50 anni.
E allora? Sicuramente, e spesso i mass media riportano casi del genere, c’è una difficoltà nel trovare la persona che può aiutare e soprattutto fornire l’autorizzazione per finalizzare il caricamento del proprio codice.
Ma… “A pensar male del prossimo si fa peccato ma si indovina”. No, non è una frase di Giulio Andreotti, come comunemente si pensa, ma “addirittura” a Papa Pio XI. Addirittura? No, non è decisamente compito di questo blog cercare di stabilire una gerarchia tra Andreotti e un Papa 😉
Per chiarire la mia posizione, ritengo molto improbabile che il 95% degli utenti Immuni che contraggono il virus incontrino difficoltà insormontabili nel finalizzare il caricamento. Penso che le motivazioni siano altre e legate, nella migliore e più ottimistica delle ipotesi, al fatto che non tutti sanno che la procedura non è automatica. Mi domando quanto costerebbe, ad esempio, stampare su ogni referto di tampone molecolare positivo una frase del tipo “Se usi Immuni, contatta il numero X appena possibile”.
Per concludere, personalmente ritengo che creare un’app assolutamente anonima sia stato un errore. Un errore comprensibile, certo.
L’app è stata infatti ideata quando l’opinione pubblica era focalizzata, come me del resto (e lo dico proprio nelle ormai lontane prime righe di questo post), sul mantenimento della propria riservatezza.
Se ogni app fosse stata associata ad un codice fiscale o ad un account SPID, ad esempio, sarebbe stato possibile comunque mantenere la riservatezza tra gli utenti (i codici sarebbero comunque stati anonimi per gli smartphone), ma si sarebbe potuto automatizzare il caricamento del codice per gli utenti infetti oppure, tramite un form o un colloquio in video con un operatore sanitario, si sarebbe potuto prenotare un tampone per i contatti con un’esposizione a rischio. Senza contare funzionalità accessorie come creare delle autocertificazioni in digitale, senza dover stampare moduli e ristamparli due giorni dopo.
Paradossalmente c’è chi in Italia ha fatto polemica, gridando alla violazione della riservatezza, per un’app che è talmente accurata nel salvaguardare la privacy degli utenti da essere praticamente… inutilizzata.
Siamo ancora in tempo (?)
Insomma detto tutto questo, e con i vaccini alle porte, vale ancora la pena installare l’app Immuni? A mio avviso sì.
Sicuramente non ci sono controindicazioni. Abbiamo visto come la privacy, oltre a non essere realmente messa in pericolo dall’app in sé, non costituisce nemmeno un tema ragionevole visto che gli smartphone sono già dei gran chiacchieroni. Insomma, se possedete uno smartphone alla privacy avete già rinunciato, che ne siate coscienti o no.
L’app Immuni è uno strumento, e se questo strumento finora non ha funzionato al meglio è perché è stato utilizzato da pochi, e quei pochi che l’hanno utilizzato non l’hanno utilizzato al meglio, non solo purtroppo per carenze organizzative e strutturali.
Lo strumento Immuni può rivelarsi ancora utile, anche perché dobbiamo tener presente che la campagna di vaccinazione sarà lunga. Anche quando sarà terminata, inoltre, dovremo verificare la reale efficacia e persistenza della copertura.
E installarla non costa davvero nulla.
A questo punto sarà la politica a deciderne il futuro. Noi cittadini possiamo solo dare un segnale.
Bel titolo per il primo post di un nuovo blog, no? Beh, lo ammetto, non è farina del mio sacco. Si comincia bene, direte voi…
La piattaforma web su cui sto scrivendo (WordPress, per chi non avesse notato il rimando in fondo ad ogni pagina) contiene un primo articolo d’esempio che si chiama proprio “Ciao mondo!”. Non ho fatto altro che mantenere il titolo originale, dunque. Ma si tratta davvero di un titolo “originale”, ovvero inedito?
I più “tech” di voi lettori sapranno che, no, non è un titolo originale. Spesso, in campo informatico, per fare degli esempi si usa spesso questa frase e la sua corrispondente in lingua inglese: “Hello, world!”.
Allora, chi è stato il primo ad aver avuto questa idea…?
Dobbiamo viaggiare indietro nel tempo fino al 1974. L’Italia è scossa dal terrorismo (piazza della Loggia e Italicus) mentre gli Stati Uniti iniziano l’anno in pieno scandalo Watergate.
Proprio negli Stati Uniti, un trentaduenne di belle speranze, Brian Kernighan, scrive un breve tutorial (ancora disponibile qui) su come utilizzare un nuovo linguaggio di programmazione realizzato dal suo collega Dennis Ritchie; i due lavorano ai Bell Labs (sì, Bell come A.G. Bell, l’inventore della telefonia) quindi non sono proprio dei parvenu della tecnologia.
Il nuovo linguaggio di programmazione si chiama C ed è destinato a soppiantare il suo predecessore, il linguaggio B; della fantasia degli informatici ne parleremo in un post a parte 😉 . Kernighan subito a pagina 1 rompe gli indugi e scrive questo “storico” esempio, un piccolo frammento di codice:
main( ) {
printf("hello, world");
}
La parola main (“principale”, in inglese) sta ad indicare che quello che segue è il gruppo di istruzioni che il computer deve iniziare ad eseguire per primo e printf (abbreviazione di print formatted, “stampa formattato”). Il testo originale è quindi “hello, world” e, se siete amanti della precisione, prendete nota delle minuscole e della virgola.
“hello, world” autografo di Brian Kernigham (1978): si nota l’aggiunta del carattere di controllo \n che indica il newline, ovvero il ritorno a capo (da Wikipedia, CC BY-SA 3.0)
Da allora “hello, world” è diventato lo standard de facto per introdurre l’utilizzo di un nuovo linguaggio di programmazione: ad oggi ne sono stati censiti ben 603 da un apposito sito.
E, sempre da allora, le belle speranze di Kernigham e Ritchie si sono concretizzate in milioni di mal di testa per altrettanti studenti di informatica. Il “Kernigham & Ritchie”, così è affettuosamente chiamato il più famoso manuale del linguaggio C, è ancora irrinunciabilmente presente nella biblioteca di chiunque si avvicini alla programmazione. Un linguaggio, il C, che infatti assolutamente non sente il passare del tempo ed è sempre nella Top Ten dei linguaggi più richiesti dal mondo del lavoro (fonte IEEE su dati CareerBuilder 2020).
Rimane però un dubbio o meglio una curiosità. A chi si è ispirato Brian Kernigham per quel suo “hello, world”?
La domanda è stata posta da Forbes India allo stesso Kernigham nel 2011, in un’occasione triste, ovvero la morte di Ritchie avvenuta il 12 ottobre dello stesso anno. La risposta non è molto soddisfacente, però.
Memory is dim now. What I do remember is that I had seen a cartoon that showed an egg and a chick and the chick was saying, “Hello, world”.
La memoria è debole, adesso. Quello che ricordo è che avevo visto un cartone animato che mostrava un uovo e un pulcino e il pulcino diceva: “Ciao, mondo”.
Un pulcino e un uovo. Già: chi si aspettava un messaggio con un significato profondo, di apertura verso il mondo reale, in un’epoca in cui i computer erano relegati in stanze dedicate, soprattutto perché avevano delle dimensioni paragonabili a grossi armadi, può legittimamente rimanere deluso.
Se voi invece siete arrivati qui e non siete rimasti troppo delusi da questo post avete superato il test del mio “numero zero”.